| 9.10. Angriffe auf Ciphersyteme - die Kryptoanalyse & die Code-Knacker |
|
|
Letztmalig dran rumgefummelt: 21.03.25 07:57:34 |
| Starke Kryptographie ist nur
ein Glied der Kette. Ihre Sicherheit wird jedoch durch das schwächste Glied
bestimmt! Kryptoanalytiker lieben codierte Textelemente mit wiederkehrenden Mustern. Sie sind der Angriffspunkt. Die schwächste Stelle bei chiffrierten Texten sowie ihre Dechiffrierung - und zwar die gewollte, ist der Schlüssel. Er muss, wenn ich kein anderes Verfahren entdecke, ausgetauscht werden - Sender und Empfänger müssen ihn besitzen. Das verhält sich erst mal prinzipiell wie der Schlüssel zu unserer Wohnung: Wer ihn hat (oder auch eine Kopie davon hat), kann rein! Darum ist die scheinbar optimale Logik: habe gar keinen Schlüssel, aber damit lässt sich dann (zumindest vorläufig) nicht mehr dechiffrieren. Also muss eine Möglichkeit gefunden werden, den Austausch der Schlüssel auszuschalten. Theoretisch geht das nicht - praktisch - mit etwas Überlegung - doch! |
|||||||||||||
|
0. CipherAttacks - Systematisierung der Verfahren 1. Das Dechiffrierprinzip 2. Codeknacken an mehreren Beispielen 3. Wie man Spuren verwischt - oder: warum Geheimdienste Finnisch und Ungarisch beherrschen ... 4. Friedmann, Babbage sowie Kasiski gegen die polyalphabetischen Code 5. Chi-Test 6. Das Knacken der deutschen Chiffre & Codes während des II. Weltkrieges 7. Knacken einfacher sowie moderner Codes und Chiffren 8. Web-Links und Tools zur Kryptoanalyse 9. Verwandte Themen |
|||||||||||||
|
|||||||||||||
|
|||||||||||||
|
|
|
||||||||||||
|
|||||||||||||
|
|||||||||||||
|
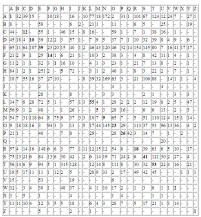
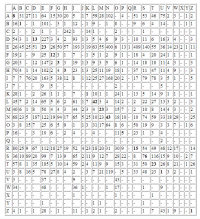
Die Angaben über die Einzelbuchstaben schwanken und hängen außerdem vom Genre des Textes ab. So schreibt Beutelsbacher: „Ein von Zitaten strotzender zoologischer Text über den Einfluss von Ozon auf die Zebras im Zentrum von Zaire wird eine andere Häufigkeitsverteilung ausweisen, als ein Traktat über die amourösen Adventüren des Balthasar Matzbach am Rande des Panamakanals.“ |
|||||||||||||
| schnell entdeckt man, dass die entscheidende Schwachstelle der monoalphabetischen Codes ihre monotone Übersetzung ein und des selben Zeichens ist - sie ist immer gleich - und das macht sie auf Grund der Häufigkeitsverteilung angreifbar | |||||||||||||
| der gewiefte Codierer geht also an die Gleichverteilung der Zeichen innerhalb einer Sprache heran - versucht genau die Spitzen zu verwischen, oder gar künstlich neue - natürlich dann falsche - zu erzeugen, was im Extremfall auch diese wieder verrät - aber so sieht das erst mal aus ... | |||||||||||||
| ... wo nämlich liegt hier meine Waffe als "Angreifer" auf einen chiffrierten Code? - richtig - an der Stelle, an welcher ich bemerke, dass die Auftrittswahrscheinlichkeit zu gleich ist - hat der Chiffrierer vielleicht ins Ungarische oder Finnische übersetzt? | |||||||||||||
Ein Kryptoanalytiker sieht sich von Fall zu Fall unterschiedlichen
Voraussetzungen gegenüber. Man unterscheidet folgende Typen von AttacKken:
|
|||||||||||||
|
| 0. Verfahren der Kryptoanalyse - CipherAttacKks - Systematisierung |
|
|
|
| Doch - was so ausschaut, als
wäre es unmöglich, ist lösbar. Völliges Kauderwelsch von Zahlen und
Buchstaben kann man schon wieder auseinander nehmen und zu interpretierbaren
Einheiten zurück übersetzen. Und wie das geht, zeigen wir nun. Im einfachsten Falle ist es die Grundidee der unterschiedlichen Häufigkeit des Vorkommens von Zeichen in einer jeweiligen Zielsprache. Das trifft auf fast alle Sprachen mehr oder weniger zu - auf die meisten jedoch mehr ;-) Nur wenige Sprachen bilden hier eine Ausnahme - sie verwenden fast alle Zeichen des Alphabets recht gleichmäßig - und: obwohl es recht bekannte Sprachen sind, fällt das kaum jemandem auf: es sind Ungarisch und Finnisch. Beide Sprachen sind, bei allen Unterschieden, historisch miteinander verwandt: beide Völker stammen aus dem indo-germanischen Raum und Finnen sind nichts weiter, als "weiter gezogene" Ungarn ;-) Wer das nicht glaubt, schlägt einfach einen Atlas auf und ermittelt die Häufigkeitsverteilung der Zeichen in Städtenamen - diese kann man statistisch getrost auf die gesamte Sprache umsetzen. Nicht umsonst arbeiten bei allen Geheimdiensten der Welt Sprachwissenschaftler, die sich mit Ungarisch und/oder Finnischem auskennen ;-) Aber was immer man sich auch einfallen lässt - und hier bilden nur die Transpositionschiffre eine wirkliche Ausnahme: immer hinterbleiben "verräterische" Muster, wie man am Beispiel des Kasiski.Tests leicht sehen kann. |
|||||||||
|
... die 4 bekannten Verfahren der Kryptoanalyse - das Logo
Das sind also die gängigen Methoden, aber noch nicht alle denkbaren. So wird in den Büchern meist folgende Methode nicht erwähnt: Geheimtext-Geheimtext-Angriff (ciphertext-ciphertext AttacKk): Das ist die Methode, bei der der gleiche Klartext mit zwei verschiedenen Methoden chiffriert wird. Der Angreifer wird auf unterschiedliche Weise daraus Nutzen ziehen; in der Regel ist eine Methode bereits gebrochen, so dass alles auf einen Klartextangriff hinausläuft. Ein solcher Angriff beruht immer auf einem Chiffrierfehler. Gute Kryptografen verwenden für jede Methode einen anderen Klartext. |
|||||||||
... Chiffrierfehler
|
|||||||||
| Angenommen, wir haben einen Geheimtext erhalten und kennen
vereinbarungsgemäß auch das Chiffrierverfahren. Wie können wir vorgehen? Zuerst benötigen wir Informationen über den Klartext, d. h. das zu erreichende Ziel: Ist der Klartext ein einfacher Text (deutsch, englisch, chinesisch?), ist er eine per Textverarbeitung erzeugte Datei (welche Textverarbeitung?), ist er eine komprimierte Datei (welches Kompressionsprogramm?), ist er eine Sprach- oder Bildaufzeichnung? Jeder dieser Klartexte hat bestimmte Eigenschaften, auf die wir testen können (haben wir das Ziel erreicht?) und die wir bei der Kryptanalyse möglichst gut ausnutzen. Ohne diese Informationen wird ein Angriff deutlich schwieriger. Es bleibt in der Regel nur, die einzelnen Textformate durchzuprobieren und zu sehen, unter welcher Annahme sich ein Angriff führen lässt. Das setzt umfangreiche Erfahrungen voraus sowie den Besitz von Software, die vermutlich nicht im Internet erhältlich ist. Wenn wir die Struktur des Klartextes kennen und das Verfahren nicht besonders einfach ist (also nicht gerade Cäsar, Substitution oder Vigenere), so betrachten wir die möglichen Schlüssel. Vielleicht gibt es gar nicht so viele Möglichkeiten. Wenn die Passwörter beispielsweise nur sechs Großbuchstaben enthalten, ergibt das ca. 300 Millionen mögliche Schlüssel. Diese Anzahl bereitet einem schnellen PC mittlerweile keine Probleme mehr. Allerdings müssen wir uns ein paar sehr schnelle Tests auf Klartext einfallen lassen. Zweckmäßigerweise werden wir stufenweise testen:
Eine typische Anwendung dieser Brute-Force-Methode ist bei der
Cäsar-Chiffrierung möglich. Als Test reicht das bloße Ansehen des Textes.
Eleganter ist natürlich eine statistische Methode, die auch die Verschiebung
sofort liefert und automatisierbar ist. |
|||||||||
| Man In The Middle-AttacK In diesem Abschnitt werden wir noch den Angriff mit ausgewähltem
Geheimtext (chosen chiphertext AttacKk) kennen lernen, der bei digitalen
Unterschriften eine Rolle spielt: Der Angreifer schiebt einen bestimmten
Geheimtext unter und hat Zugriff zum daraus erzeugten »Klartext«. Aus diesen
Informationen kann er andere Klartexte berechnen, ohne dass der Chiffrierer
diesen Angriff nachweisen könnte. Ziel jedes Kryptografen ist es natürlich, einen Algorithmus zu entwerfen,
bei dem die Kryptanalyse keine praktisch verwertbaren Ergebnisse liefern
kann. Das heißt also nicht, dass Kryptanalyse unmöglich wird, sondern dass
sie zu lange dauern würde (inzwischen wäre die chiffrierte Information
wertlos geworden) oder dass sie wesentlich teurer würde, als es dem Wert der
Information entspräche.
Ein Kryptograf muss also immer Kryptologe sein, d. h. auch die
Kryptanalyse beherrschen. |
|
| 1. Das Dechiffrierprinzip |
|
|
|
| Doch - was so ausschaut, als
wäre es unmöglich, ist lösbar. Völliges Kauderwelsch von Zahlen und
Buchstaben kann man schon wieder auseinander nehmen und zu interpretierbaren
Einheiten zurück übersetzen. Und wie das geht, zeigen wir nun. Grundidee ist die unterschiedliche Häufigkeit des Vorkommens von Zeichen in einer jeweiligen Zielsprache. Das trifft auf fast alle Sprachen mehr oder weniger zu - auf die meisten jedoch mehr ;-) Nur wenige Sprachen bilden hier eine Ausnahme, verwenden fast alle Zeichen des Alphabets recht gleichmäßig - und: obwohl es recht bekannte Sprachen sind, fällt das kaum jemandem auf: es sind Ungarisch und Finnisch. Beide Sprachen sind, bei allen Unterschieden, historisch miteinander verwandt: beide Völker stammen aus dem indo-germanischen Raum und Finnen sind nichts weiter, als "weiter gezogene" Ungarn ;-) Wer das nicht glaubt, schlägt einfach einen Atlas auf und ermittelt die Häufigkeitsverteilung der Zeichen in Städtenamen - diese kann man statistisch getrost auf die gesamte Sprache umsetzen. Nicht umsonst arbeiten bei allen Geheimdiensten der Welt Sprachwissenschaftler, die sich mit Ungarisch und/oder Finnischem auskennen. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Frequenzanalyse & Kontaktanalyse wir haben mal gezählt: 24999 mal das "E" in Goethes "Faust" Teil I das sind ca. 17,2 % aller Zeichen (Zeichen sind dabei lediglich die Buchstaben!) Goethes Faust in Zahlen Habe nun, ach! Philosophie, Juristerei und Medizin, Und leider auch Theologie Durchaus studiert, mit heißem Bemühn. Da steh ich nun, ich armer Tor! Und bin so klug als wie zuvor; Das sind die wohl jedem bekannten, ersten 30 Wörter, die Goethe seinem Faust in den Mund legt. Anschließend kommt Faust noch ganze 221-mal zu Wort. Mephistopholes läuft ihm dabei aber den Rang ab. Mit insgesamt 254 Passagen ist er einsamer Spitzenreiter. Gretchen steht weit abgeschlagen mit 76 Äußerungen an Platz 3. Was meinen Sie wohl, wie es mit der Worthäufigkeit aussieht? - Na? Sicher können Sie es sich schon denken: „und" hat sich mit 918 Vorkommen an die Spitze gesetzt. Das sind immerhin 0,35% von insgesamt mehr als 30000 Wörtern. Hierbei verwendet Goethe ungefähr 6300 verschiedene; also jedes Wort im Durchschnitt 5-mal. Gefolgt wird "und" von "ich", "die" und "der". Das häufigste Substantiv ist "Welt" mit 53 und das häufigste mehrsilbige Wort "einen" mit 65 Auftreten. In "Der Tragödie 2. Teil" hat sich Goethe noch gesteigert. Insgesamt über 45000 und davon ungefähr 10000 verschiedene Wörter hat er hier niedergeschrieben. Das Wort "und", 1181-mal zu lesen, ist nach wie vor an der Spitze. Auch Mephistopholes ist mit 188 Zu-Wort-Meldungen wieder der geschwätzigere, gefolgt von Faust mit 126. Faust I in Zahlen: Gesamtwortanzahl: 30897 verwendete Wörter: ca. 6300 Worthäufigkeit: und (918), ich (701), die (668), der (605), nicht (426) Redeabschnitte: MEPHISTO (254), FAUST (222), MARGARETE (76), MARTHE (40) Faust II in Zahlen: Gesamtwortanzahl: 45045 verwendete Wörter: ca. 10000 Worthäufigkeit: und (1181), die (888), der (864), ich (813), das(602) Redeabschnitte: MEPHISTO (188), FAUST (126), KAISER (60), CHOR (57) Thema dieser Ausgabe: Texte in Zahlen __________________________ wortwoertlich, Januar 2003 Fragen an mich@diaware.de Im Netz www.diaware.de |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Um Kryptoanalyse betreiben zu können, müssen wir uns mit den
Gesetzmäßigkeiten der Sprache vertraut machen. Solche Normen hat jede
Sprache und kann auch durch geschickte Chiffrierung nicht vollständig
beseitigt werden:
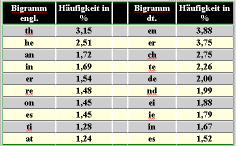
Muster sind die Art und Weise, wie sich Buchstaben in einem Wort wiederholen. Sie werden über Ziffern ausgedrückt, wobei jeder neue Buchstabe auch eine neue Ziffer erhält, also z.B.: OTTO č 1221 NGRGUUV č 1232445 PANAMAKANAL č 12324252326 Solche Muster bleiben bei der monoalphabetischen Chiffrierung erhalten, d.h. enthält ein Geheimtext keine Muster, so ist er nicht durch monoalphabetischer Chiffrierung entstanden. Muster sind sehr hilfreich bei kurzen Texten
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
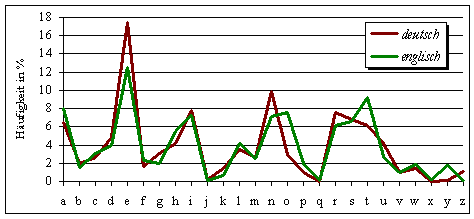
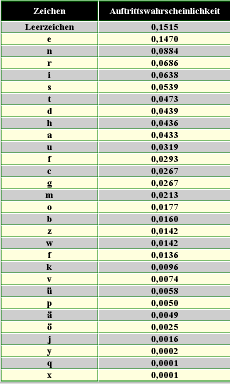
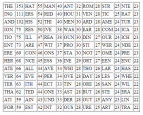
Buchstabenhäufigkeiten in ausgewählten Sprachen
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
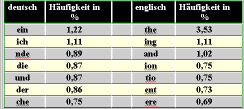
das Verfahren beruht auf der Tatsache,
"... dass die _ehn haeu_i_sten _u_hsta_en
i_ Deuts_hen bereits drei _ierte_ des _esa_ttextes _i_den." das Verfahren beruht auf der Tatsache, "... dass die zehn häufigsten Buchstaben im Deutschen bereits drei viertel des Gesamttextes bilden." |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fazit: allein mit einem "Angriff" reiner Statistik wird man schon bei einfachen Chiffren nichts (und das ist das Ende der Computerwelt!!!). In zweiter Instanz gehört eine "semantische" Zuordnung der jeweils gefundenen Zeichen dazu - das ist dann der Mensch, der in Zusammenhängen denken kann, was dem Computer derzeit versagt bleibt (das wäre dann echt künstliche Intelligenz). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2. Code knacken an mehreren Beispielen |
|
|
|
|
|
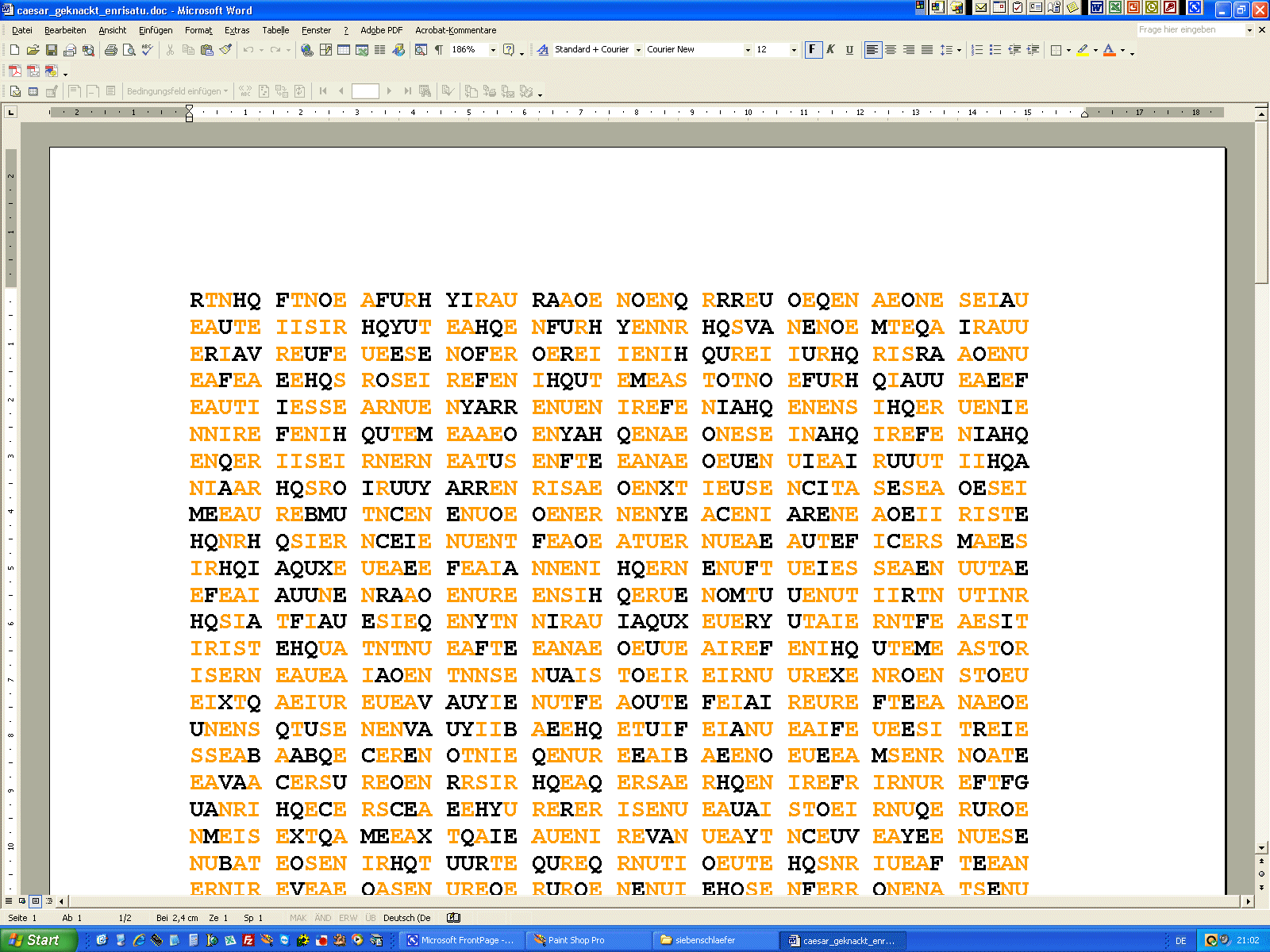
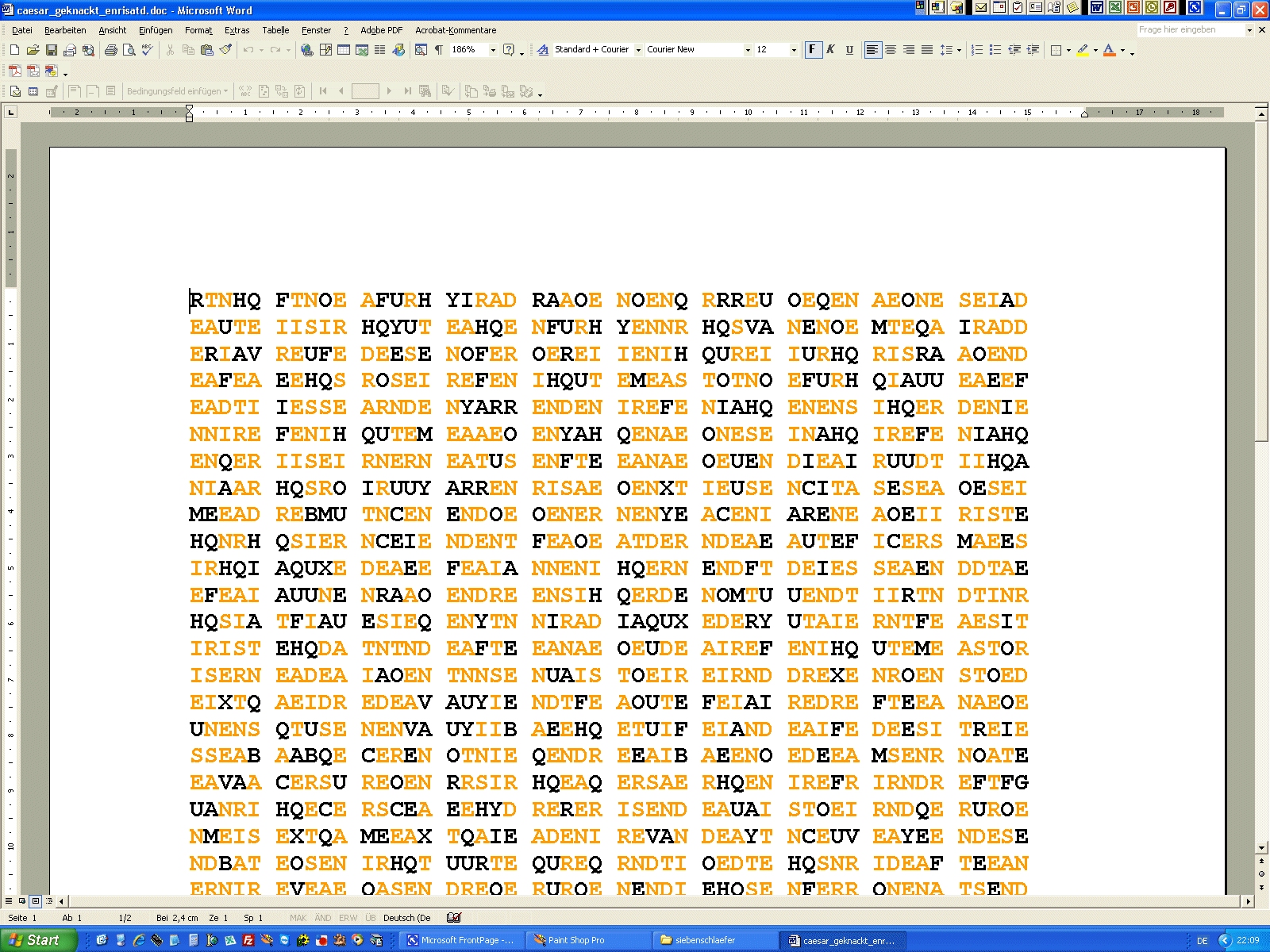
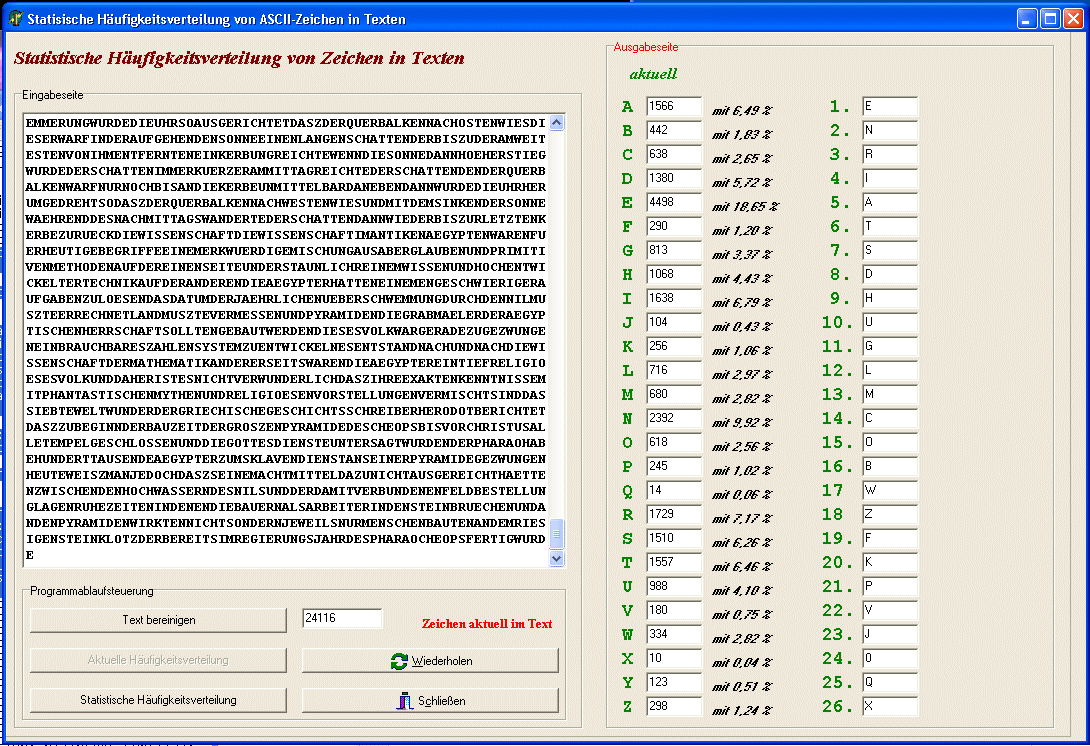
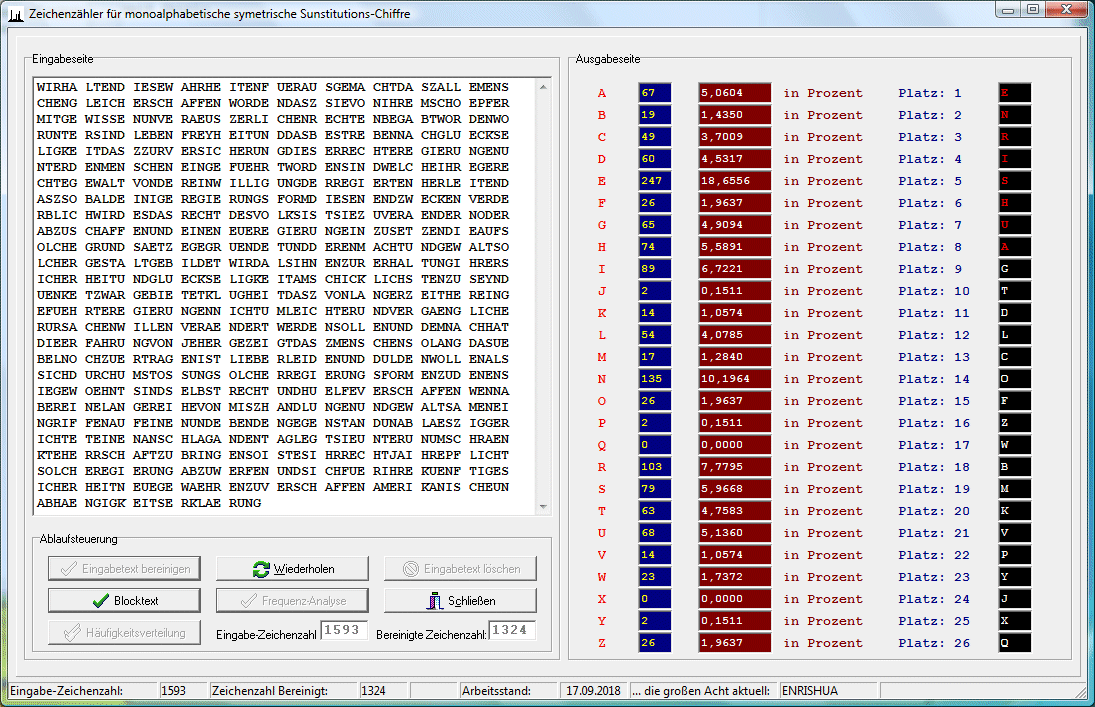
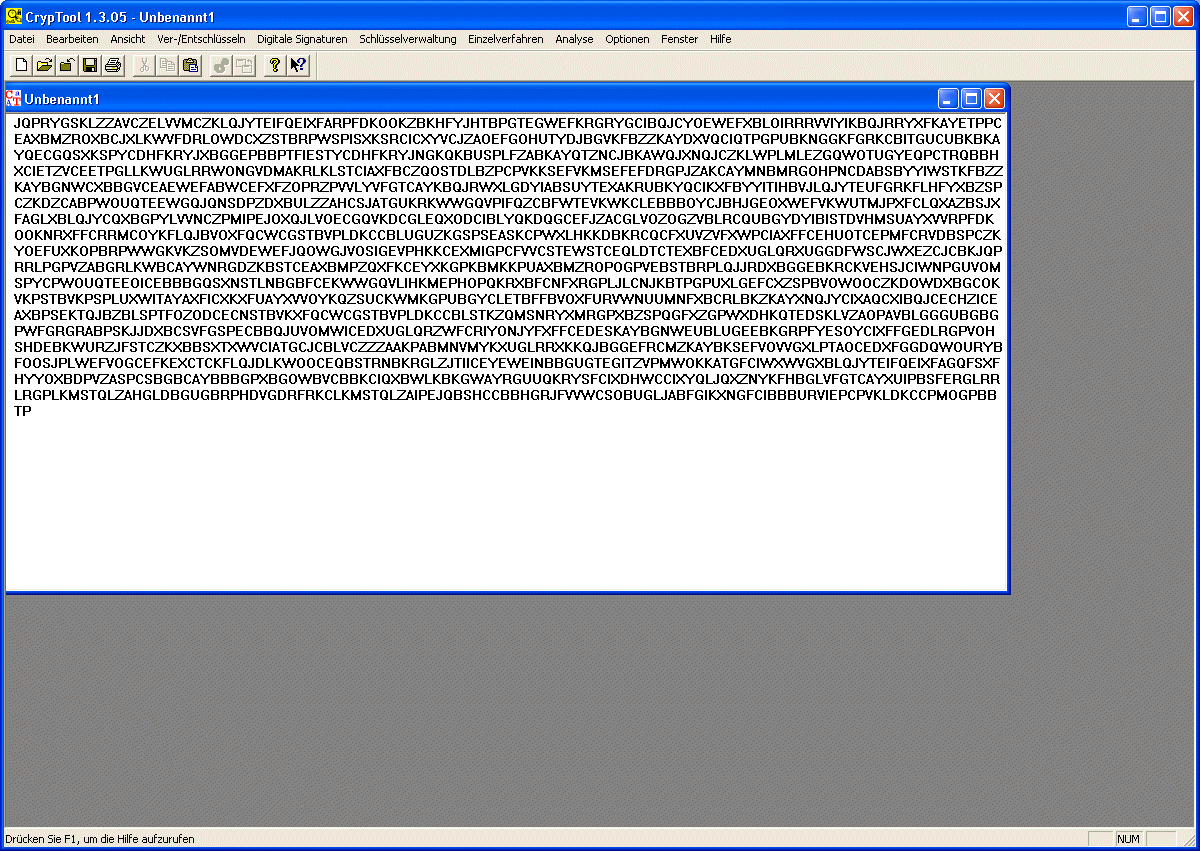
Im folgenden nun einige simple, aber doch schon funktionierende Versuche, chiffrierte Texte zu knacken, wobei wir vom einfachen zum schwierigeren übergehen. Vorerst gibt's nur Beispiele für monoalphabetische Chiffre und hierbei muss nicht einmal der Schlüssel ermittelt werden. Durch Häufigkeitsanalyse kann man den Klartext ermitteln. Aber siehe unter 3. auch die Möglichkeiten, genau dies einzuschränken!!! | ||||||||||
|
|||||||||||
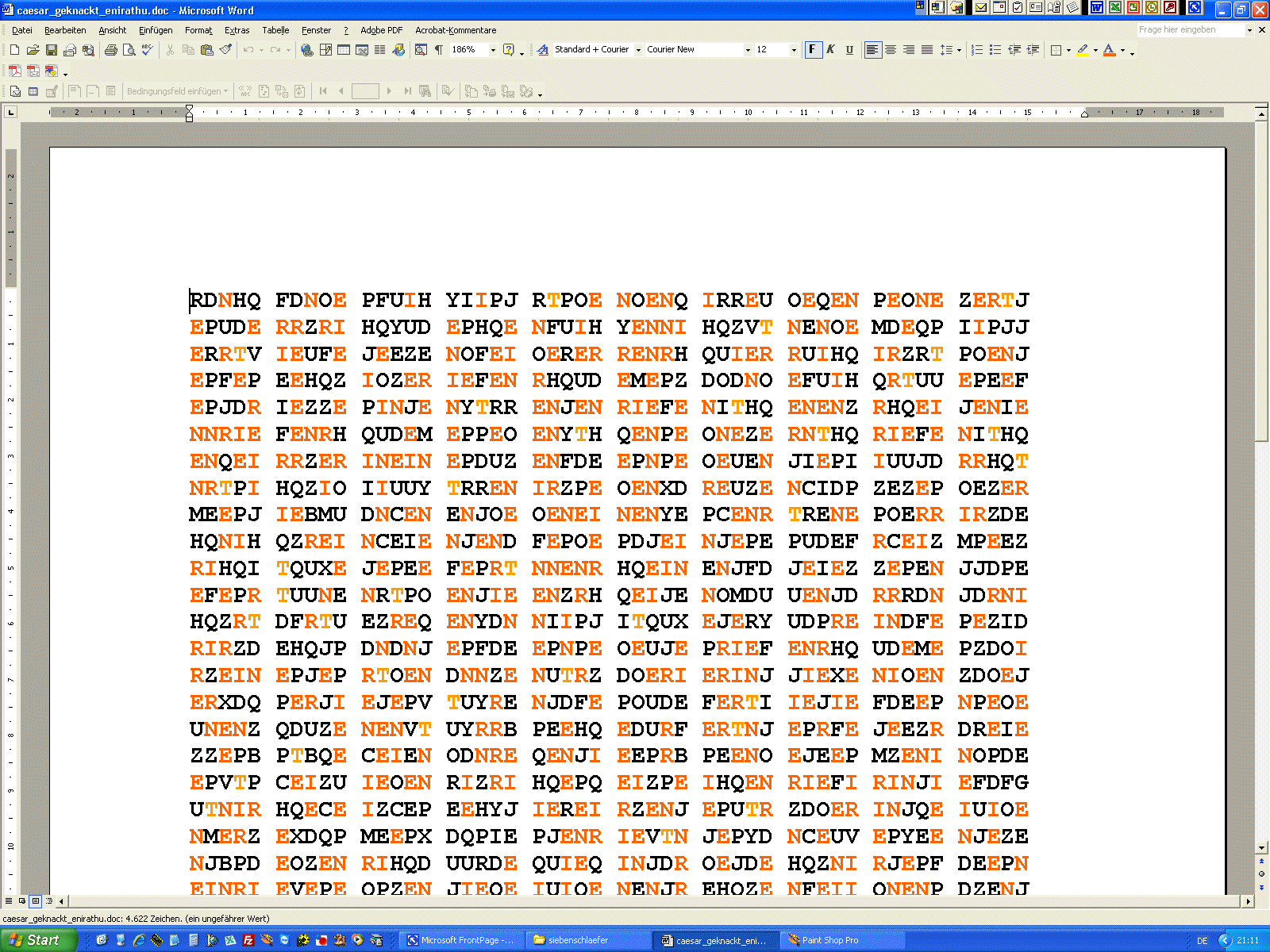
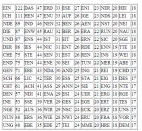
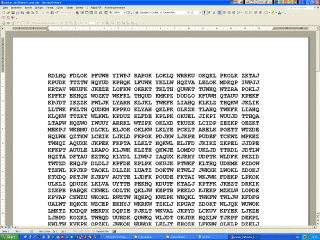
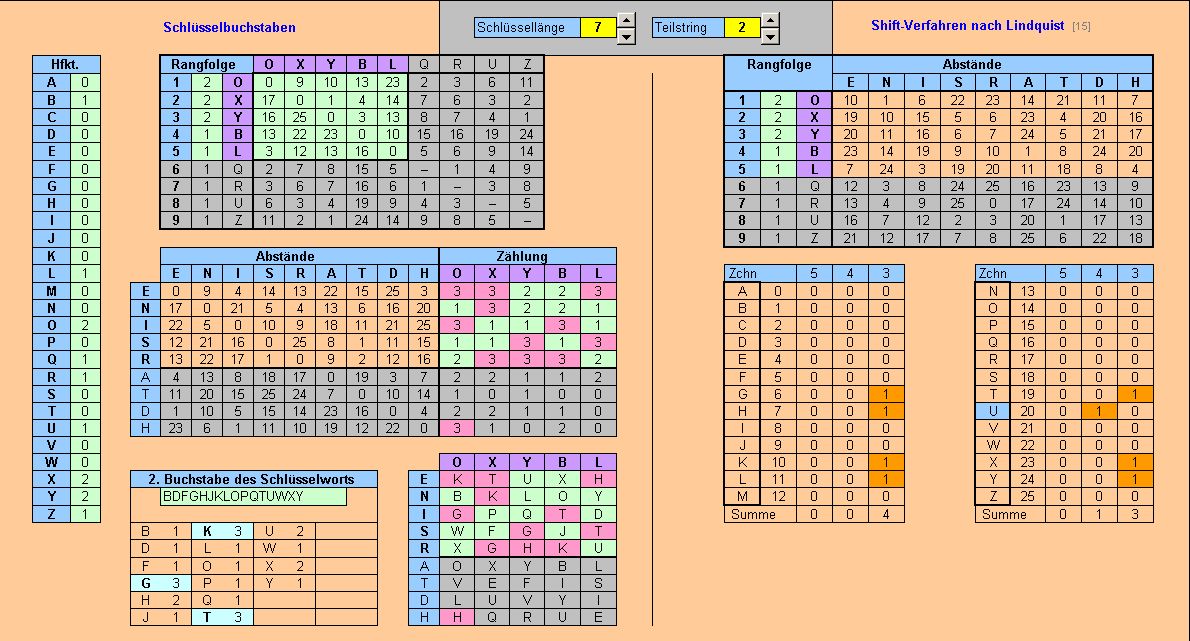
Zählen der Häufigkeit der Buchstaben Der Buchstabe G tritt am häufigsten auf, deshalb vermuteten wir: G = e ... wie das weiter geht, findet man hier!!! |
|||||||||||
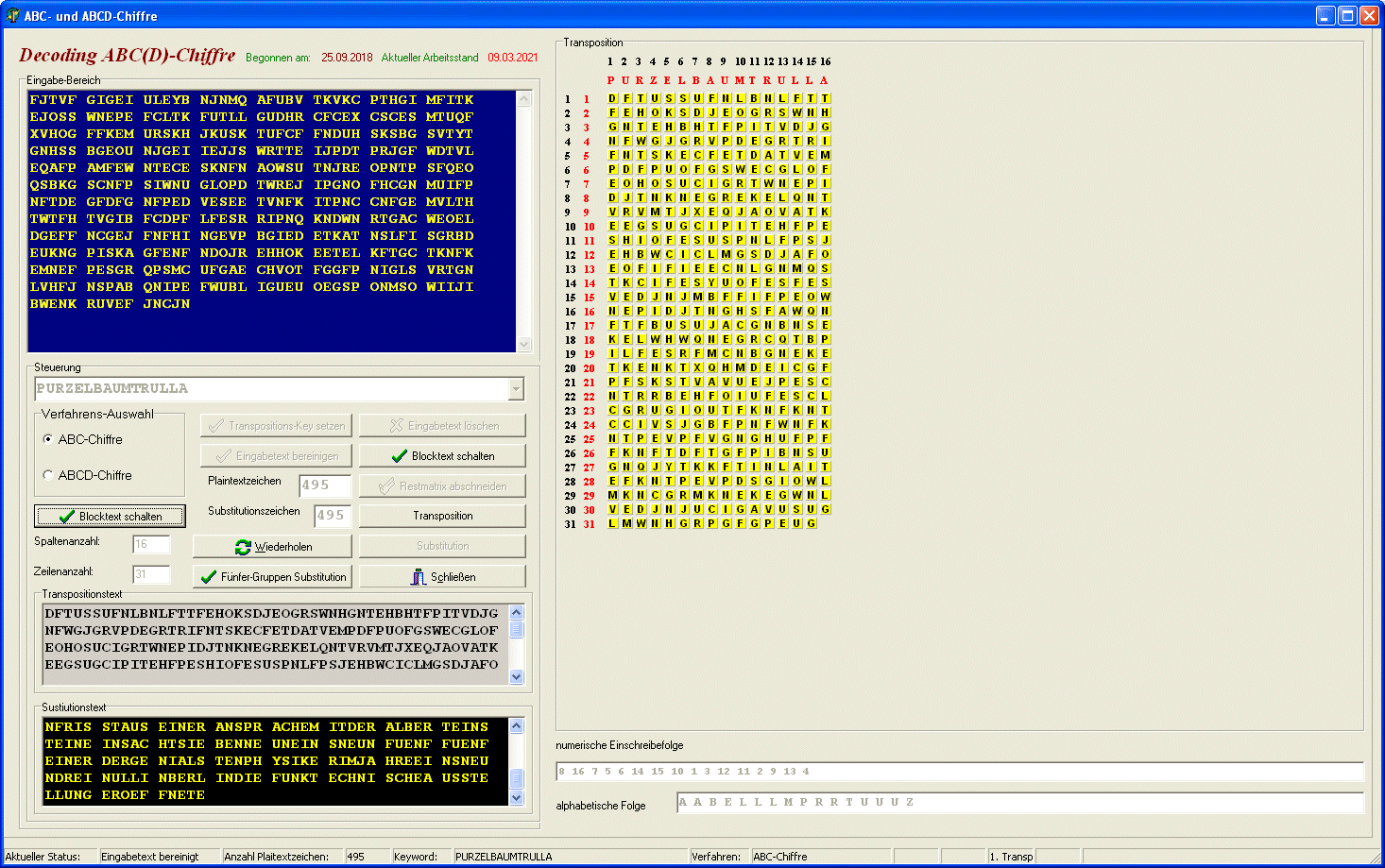
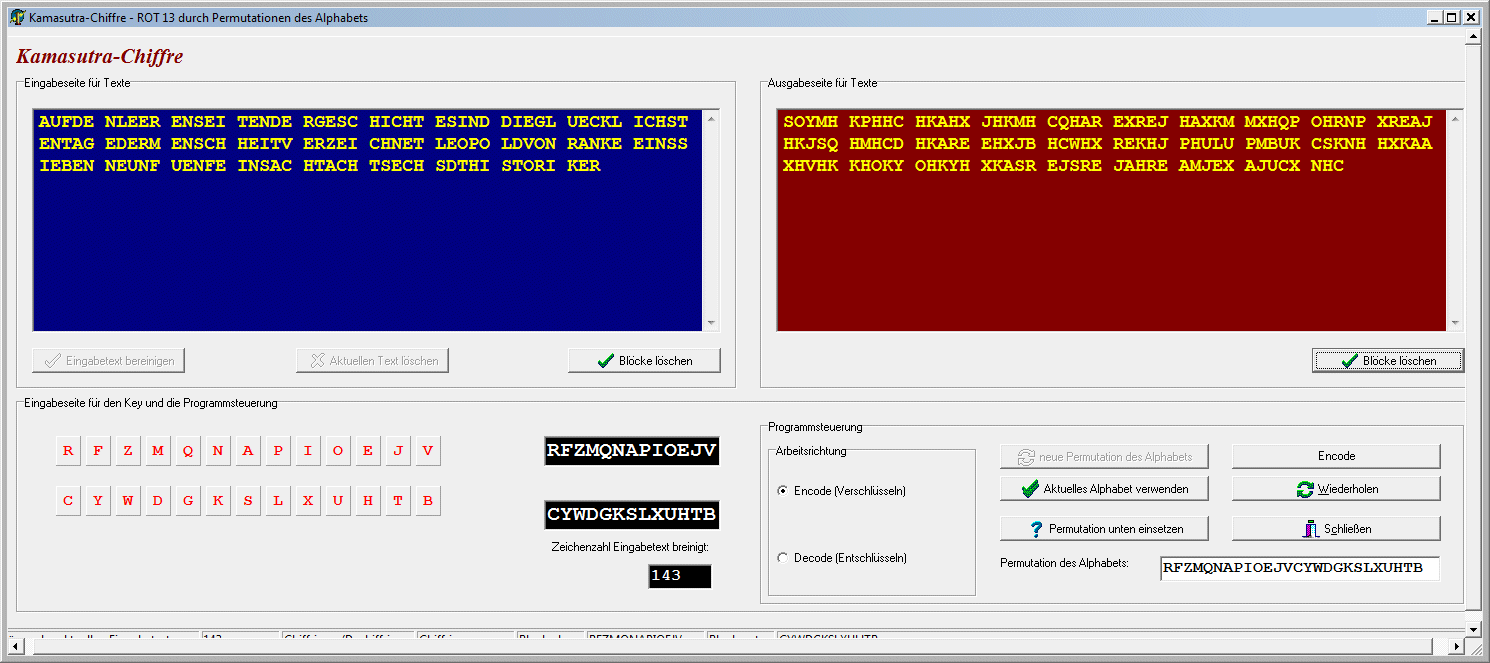
| Handlungsbeispiel 1 zu monoalphabetisch verschlüsseltem Substitutionscode | |||||||||||
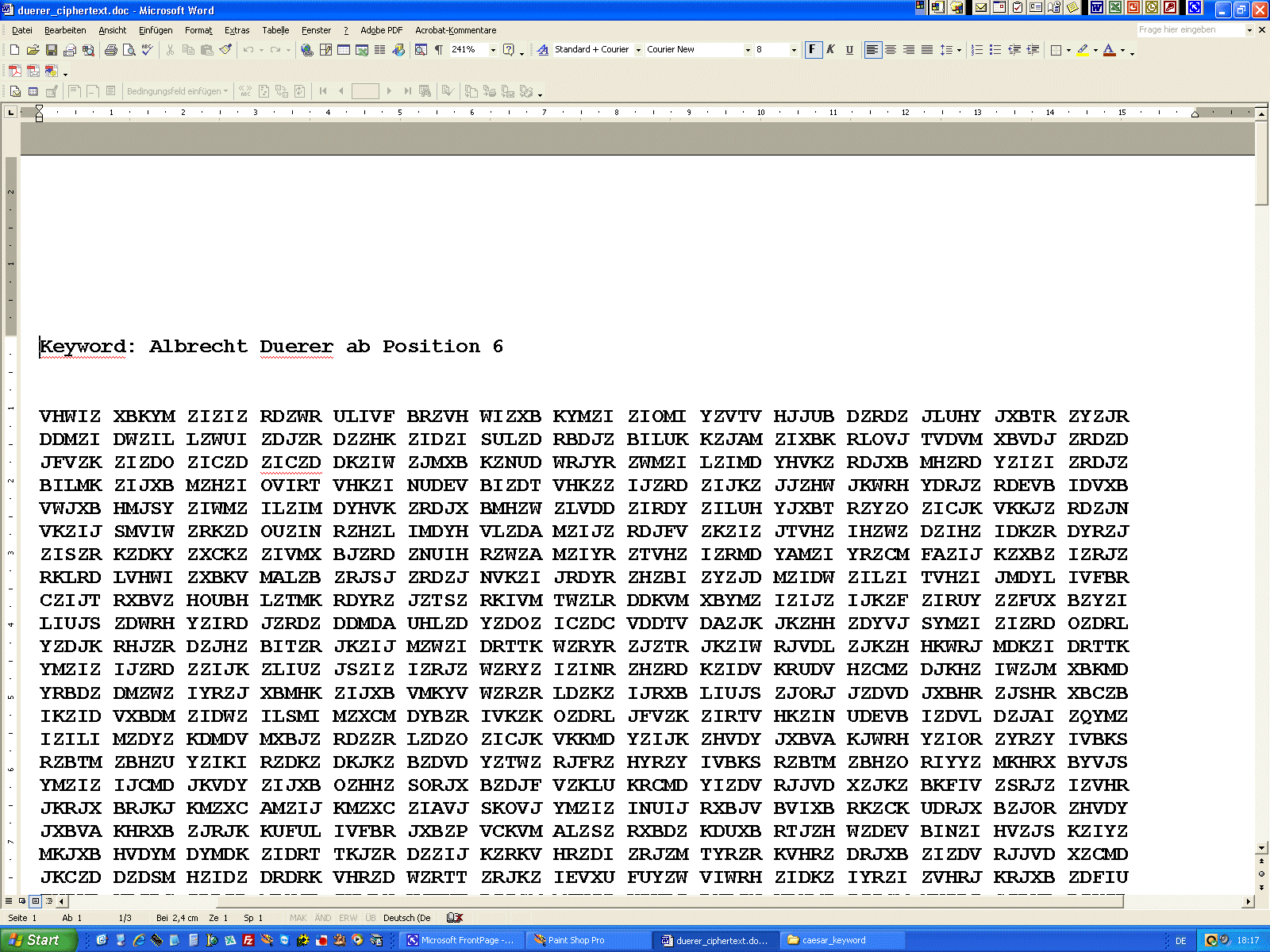
... ist eine Teilmenge von Zeichen dechiffriert, so ist das weitere
"Aufrollen" des Plaintextes dann immer einfacher: CÄSAR-Chiffre mit Keyword
|
|||||||||||
|
|||||||||||
|
|
|||||||||||
| 3. Wie man Spuren verwischt - oder warum Geheimdienste Finnisch und Ungarisch beherrschen |
|
|
|
|
|
Alles, was einen
Code in der vermuteten Übersetzung in die Normalverteilung der jeweiligen
Zielsprache bringt, macht ihn angreifbar. Ergo muss genau diese
Normalverteilung verwischt werden, ohne jedoch zu verschwinden. Und damit
bleibt das Problem eigentlich erhalten, denn: dass ich das als Chiffrierer
versuche, weiß ja auch der potentielle Angreifer - der wiederum seinerseits
mich natürlich nicht wissen lassen wird, dass er längst mit liest - das
"Mitlesen" der ENIGMA-Chiffre in Bletchley Park ist beredtes Beispiel für das
Leben dieser Theorie. Und zu allem Überfluss kommt heutzutage noch ein Fakt, den der Laie natürlich nicht kennt, hinzu: es gibt ein, durchaus berechtigtes Interesse, jeden auch noch so komplex verschlüsselten Code, mitzulesen. Das wünschen sich alle Geheimdienste dieser Welt - und deshalb gilt: es darf alles so stark verschlüsselt sein, das Du und ich nicht ohne weiteres Angreifen können - unser Staat aber, will bei Bedarf genau dieses - und zwar immer und mit Sicherheit! |
| Gleichverteilung der Zeichen organisieren | |
| Text verfremden nach dem Muster: „Ein von Zitaten strotzender zoologischer Text über den Einfluss von Ozon auf die Zebras im Zentrum von Zaire wird eine andere Häufigkeitsverteilung ausweisen, als ein Traktat über die amourösen Adventüren des Balthasar Matzbach am Rande des Panamakanals.“ |
| 4. Friedmann, Babbage sowie Kasiski und die polyalphabetische Codes |
|
|
|
|
|
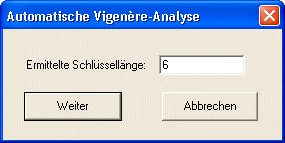
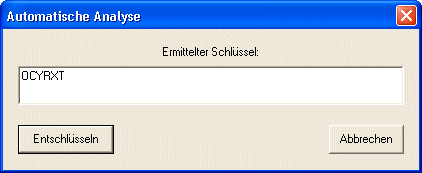
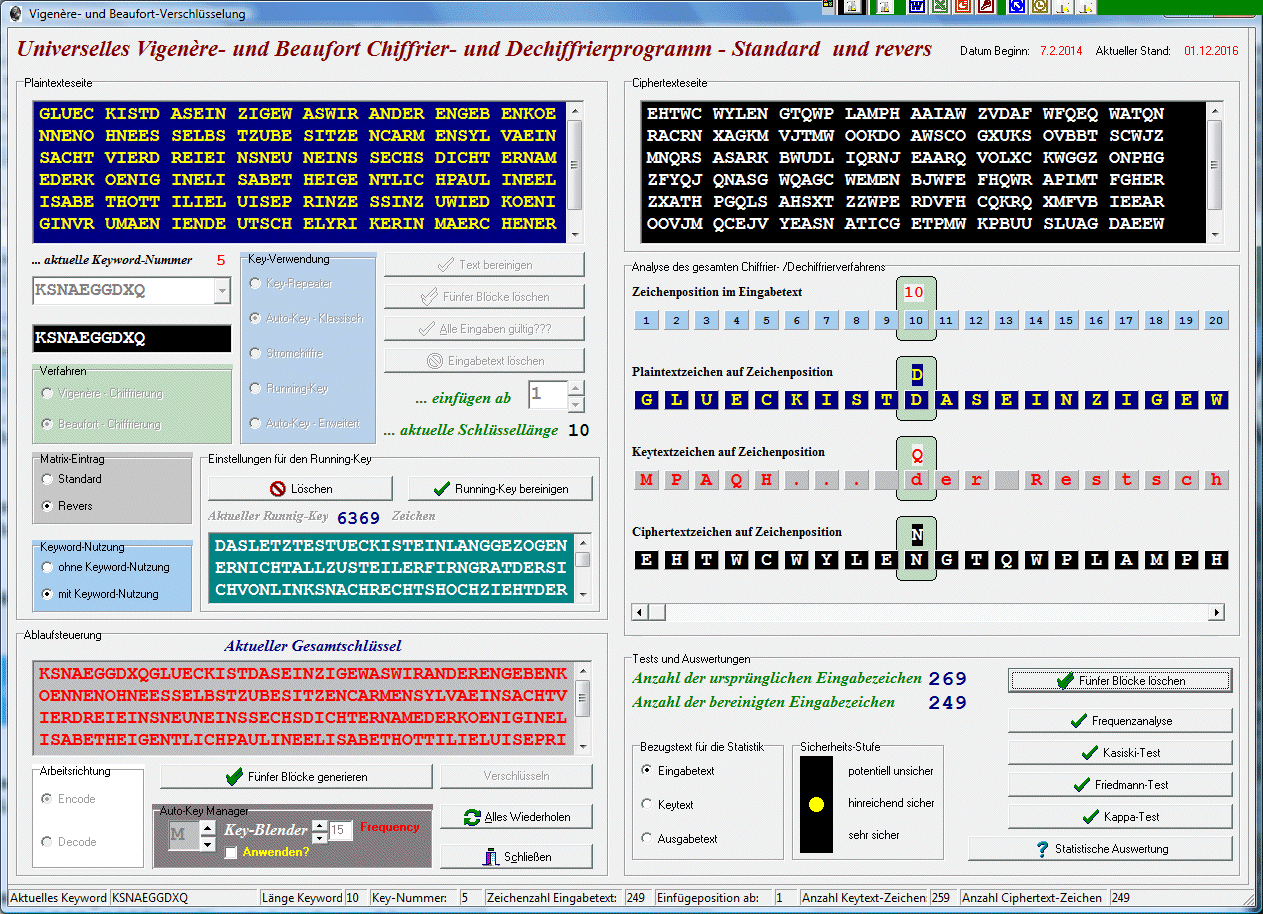
... nun - erst einmal einige hundert Jahre gar nicht. bis man dann auf die Idee der Überführung auf Grundoperationen kam. Alle höheren mathematischen Operationen lassen sich auf einen Addition zurückführen. So machen wir's auch mit den Codes! Wir suchen den Übergang zum monoalphabetischen Schlüssel und knacken den Code dann, als wär's ein solcher! | ||||||||||||||||||
|
|||||||||||||||||||
was heute mit relativ "einfachen" Mitteln und Logik zu knacken geht ...
|
|||||||||||||||||||
|
|||||||||||||||||||
... und nun das Übungsbeispiel dazu:
|
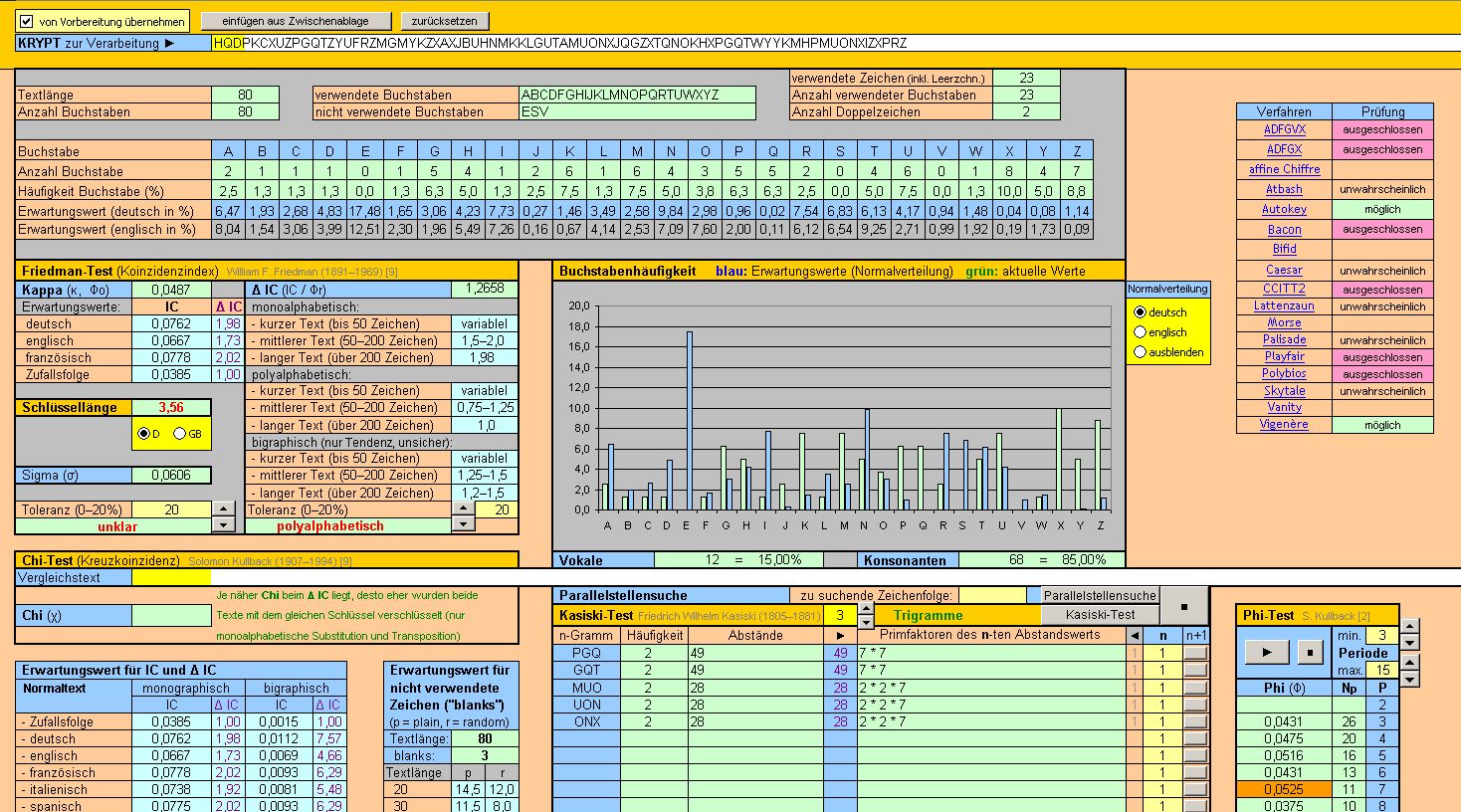
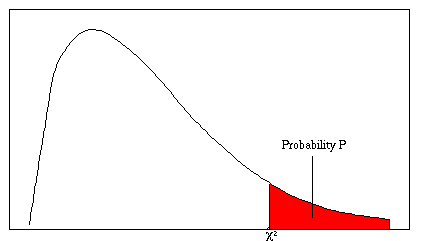
| 5. Der Chi-Test |
|
|
|
|
|
Eine besondere rolle spielt hier wohl die deutsche Chiffriermaschine ENIGMA. An dieser waren nicht nur die Engländer selbst beteiligt, nein, bereits polnische Kryptonalytiker sowie die Codebücher aufgebrachter U-Boote brachten hier Erleichterung, wennglich immer noch genügend Analyse-Arbeit mit dem Kopf zu machen war. |
|
... der CHI-Test |
| 6. Das Knacken der deutschen Chiffre & Codes während des II. Weltkrieges |
|
|
|
|
|
Eine besondere rolle spielt hier wohl die deutsche Chiffriermaschine ENIGMA. An dieser waren nicht nur die Engländer selbst beteiligt, nein, bereits polnische Kryptonalytiker sowie die Codebücher aufgebrachter U-Boote brachten hier Erleichterung, wennglich immer noch genügend Analyse-Arbeit mit dem Kopf zu machen war. | ||||||||
|
|
|||||||||
|
|||||||||
|
... und was es zu knacken galt: ENIGMA Lorenzmaschine Schlüsselzusatzgerät 41 |
| 7. Das Knacken einfacher sowie moderner Codes und Chiffres |
|
|
|
|
|
Hier nun ziehen neben der reinen Logik, Mathematik, Rhetorik, Mustersuche eben auch andere wissenschaftlich Disziplinen ein. Die Informatik hat die Physik (eigentlich schon lange, aber jetzt aktuell ganz neu) sowie die Biologie für sich entdeckt - und: es gelten die alten Regeln mit ihrem Hauptsatz: Unterschätze nie Deinen Gegner - den unknackbaren Code gibt es nur theoretisch - praktisch allenfalls eine hohe Sicherheit! | ||||||||
|
|||||||||
|
| 8. Weblinks und Tools zur Kryptoanalyse |
|
|
|
|
|
Die Rotor-Chiffriermaschine Enigma ist wahrscheinlich die bekannteste und populärste historische Chiffriermaschine. Mit ihr werden im Zweiten Weltkrieg die meisten Funksprüche der deutschen Wehrmacht und Marine vor dem Senden verschlüsselt und nach dem Empfang schließlich wieder entschlüsselt. Vermutlich wurden etwa 100 000 bis 200 000 Enigmas hergestellt. Der Großteil wird jedoch im Krieg und direkt danach zerstört. | ||||||||||||||||
|
| 9. Verwandte Themen |
|
|
|
|
|
Da monoalphebetische Chiffren die Mutter alles Verschlüsselungstechniken waren, sind sie zu faktisch jedem Bereich der Kryptologie verwandt. Und da via Computer die Krptologie auch etwas mit Binärmustern zu tun hat, gibt es auch ein reizvolles Verhältnis zur Logik. | ||||||||||||||||
|
|||||||||||||||||
|
|
zur Hauptseite |
© Samuel-von-Pufendorf-Gymnasium Flöha | © Frank Rost November 2003 |
|
... dieser Text wurde nach den Regeln irgendeiner Rechtschreibreform verfasst - ich hab' irgendwann einmal beschlossen, an diesem Zirkus nicht mehr teilzunehmen ;-) „Dieses Land braucht eine Steuerreform, dieses Land braucht eine Rentenreform - wir schreiben Schiffahrt mit drei „f“!“ Diddi Hallervorden, dt. Komiker und Kabarettist |
|
Diese Seite wurde ohne Zusatz irgendwelcher Konversationsstoffe erstellt ;-) |

















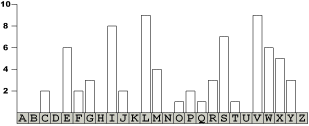














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}