| Post'sches Korrespondenzproblem |
|
|
Letztmalig dran rumgefummelt: 09.12.07 15:05:54 |
| Das Post'sche
Korrespondenzproblem ist ein wichtiges Entscheidbarkeitsproblem. Die
Nichtentscheidbarkeit des Post'schen Korrespondenzproblems wurde erstmals
1946 von dem Mathematiker E. L. Post (1897 - 1954) bewiesen. Korrespondenz
ist eine eindeutige Zuordnung!!! Voraussetzungen: Gegeben sind:
|
|||||
|
1. Problembeschreibung 2. Hintergründe und Zusammenhänge - Einordnung in Klassen 3. Lösungsalgorithmen 4. Programmvorschläge 5. Zusammenfassung 6. Weiterführende Literatur 7. Linkliste zum Thema 8. Verwandte Themen |
|||||
|
|||||
Quellen:
|
|||||
| der "Worst-Case" liegt hier sicher nicht in der Komplexität zum Aufwand für den Lösungsalgorithmus - er ist hier allein in der Mächtigkeit des Problems zu suchen | |||||
|
die Anzahl der Zwischenwerte, die zur Lösung für ein Argument benötigt werden ist schlichtweg enorm und steigt mit n-polinomial |
|||||
| Beachte vor allem bei Problemlösungsalgorithmen: Murphys Gesetze sowie deren Optimierung durch Computer sowie deren Optimierung durch Computer |
| 1. Problembeschreibung |
|
|
|
|
Das Post'sche Korrespondenzproblem ist definiert:
Gibt es zu einer gegebenen endlichen Relation R A* A* ein Paar (x, y) A+ mit
x = y? x heißt dann Korrespondenz. Anders formuliert wird versucht, aus der
Menge der möglichen Wortpaare von x und y ein gleiches Wort zu bilden. Dabei
muss aber aus jeder Menge das Wort mit dem gleichen Index zugeordnet werden.
Bei Gleichheit ist Korrespondenz gegeben.
Bemerkung: Es gibt keinen Algorithmus, der das
allgemein entscheidet. Für spezielle Fälle ist eine Entscheidung möglich.
Stellen Sie für die folgenden Beispiele fest, ob eine Korrespondenz
existiert !
Die endliche Liste von Paaren hat eine Korrespondenz, wenn es eine Indexfolge I = (i1, ...,ik) mit k ε N , ij Î {1, ..., n}, 1 Ł j Ł k gibt, so dass x i1. . . xik = yi1 . . . yik gilt. |
|
| das übersetzen wir jetzt mal für den Normalsterblichen, denn hier steht nix weiter, als: "... lässt sich mit einer gegebenen Wertemenge und daraus zusammengestellten Kombinationen eine | |
|
Die Suche nach Korrespondenz zweier Prüfworte, welche durch Anfügen von
Zeichen aus Gruppen von Wortpaaren mit jeweils gleichem Index erfolgen.
Vorstellen können Sie sich die Lösung dieses Problems, wenn bei einem
Familienausflug mit mehreren Gruppen jeweils unterschiedlicher Anzahl
verschiedener PKW 's versucht wird, zwei Autokolonnen mit jeweils gleichen
Fahrzeugen zu bilden. Das setzt zum Beispiel voraus, dass es zwei gleiche |
|
|
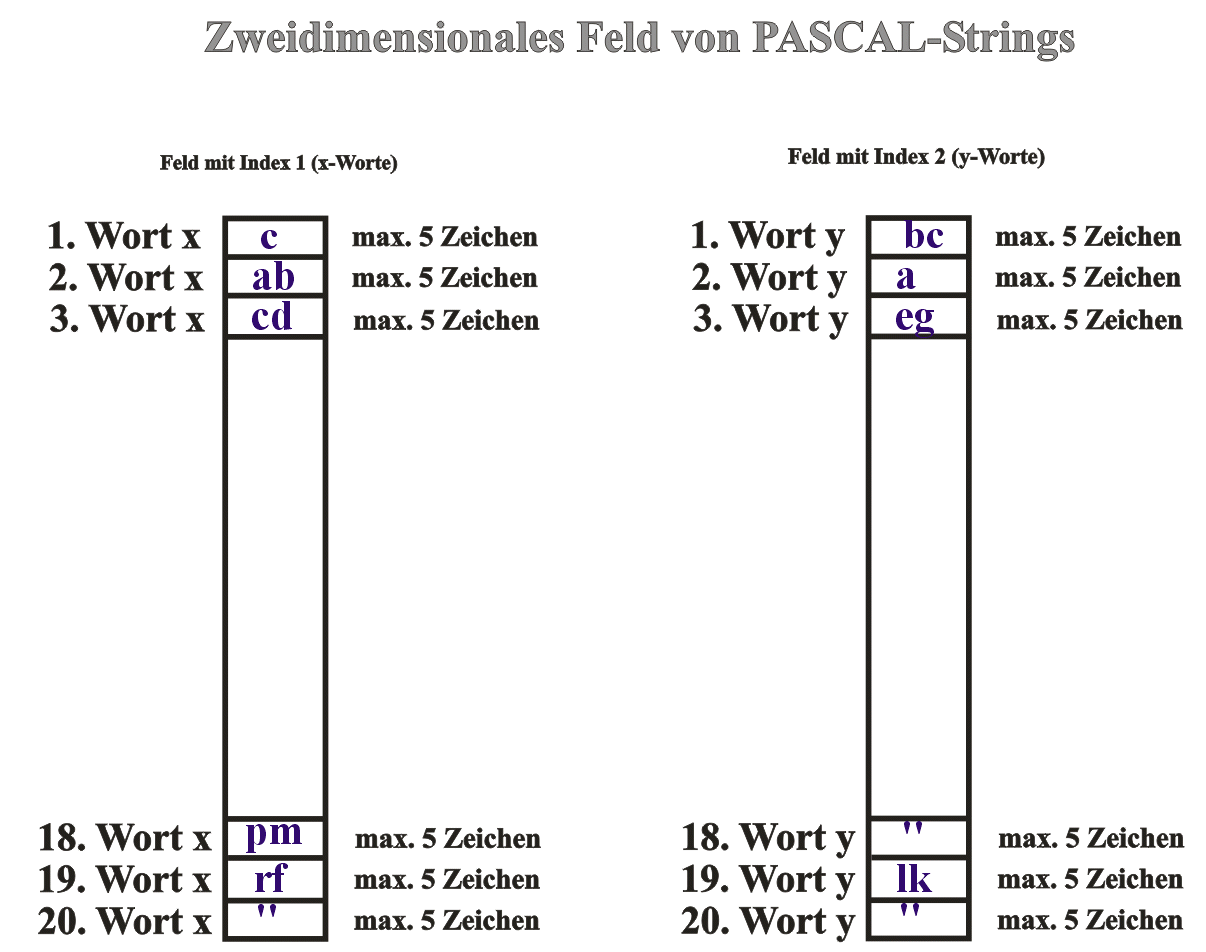
Alphabet A = {0,1} Paarvorrat P = {(1,111),(10111,10),(10,0)} Zuordnungsversuche:
|
| 2. Hintergründe, Zusammenhänge - Einordnung in Klassen |
|
|
|
|
|
Der Lösungsalgorithmus für die Türme von Hanoi |
| effiziente Lösung nur als rekursiver Algorithmus | |
| reale Problemlösungsversuche scheitern an den Dimensionen der verfügbaren Datentypen - für die Mehrheit aller Fälle ist die Lösungsmenge für ein gegebenes Wortpaar unendlich |
| 3. Lösungsalgotihmus |
|
|
|
|
|
Wenn es mindestens einen Lösungsansatz gibt, dann versuche, aus den gegebenen Wortpaaren identische Sätze auf beiden Seiten der Gleichung zu bilden. Wiederhole dies solange, bis keine weitere Möglichkeit mehr existiert. |
|
|
|
|
A={a, b} mit den Paaren P = ((bbb, bb), (abb, babbb))
Indexmenge: {1,2,1} |
|
|
A = {a, b} mit den Paaren P = ((a, ba), (bba, aaa), (aab, ba)) Keine Korrespondenz, da kein Element x und y mit gleichen Zeichen beginnt |
|
|
A = {a, b, c} mit P = ((c, bc), (ab, a))
Indexmenge: {2,1} |
|
|
A = {a, b} mit P = ((a, baa), (ab, a), (b, aab))
Indexmenge: {2,1,1,1,1,1,1,1,3} |
|
|
A = {a, b, c} mit P = ((a, b), (b, c), (a, abcb), (bc, a))
Indexmenge: {3,4,2,1} |
|
|
Nennen Sie zwei Korrespondenzen für A = {a, b, c} mit P = ((a, b), (b, c), (a, bbcb), (b, ba),(cbb, b)) !
Indexmenge: {4,1,4,2}
Indexmenge: {4,3,4,2,5,3,5,2,5,5} |
|
|
A = {0, 1} mit P = ((0111, 1), (0, 001), (10, 1))
aber:
Indexmenge: {2,2,3,1} |
|
|
A = {0, 1} mit P = ((0, 00), (00, 010), (010, 100), (100, 0100))
Indexmenge: {1,2,4,4,3} |
| 4. Programmvorschläge |
|
|
|
|
|
Das erste und vorläufig einzige Beispiel stellt ein PASCAL-Programm vor, welches die Unentscheidbarkeit immerhin bis 64 KByte Zeichen hinauszögert, Lösungen im oben genanten Sinne kann es für nicht unentscheidbare Kombinationen keine geben - auch der größte Computerspeicher ist endlich in seinem Speichervolumen :-( |
| PROGRAM postsches_korrespondenzproblem (INPUT,OUTPUT); USES WINCRT,STRINGS; CONST hilfstext:BOOLEAN=FALSE;{vordefinierte Variable, welche verwaltet, ob Hilfstexte angezeigt werden sollen!} abbruch:BOOLEAN=FALSE;{Variable zum Programmabbruch im Sinne von Beenden} index_dimension=36166;{Dimension der zur Anzeige gelangenden Indizies} c_dimension=65535;{Dimensionierung der C-Strings} stringdimension=5;{Standarddimension der PASCAL-Strings - kann verändert hier werden} TYPE t_wortpaar=ARRAY[1..20,1..2] OF STRING[stringdimension];{hinterlegt die Wortpaare für die Wortfolge x (1) und y (2)} VAR wiederholung:CHAR;{Steuert die Abfrage der Programmwiederholung} nochmal:CHAR;{Steuerung der Programmwiederholung nach Fehlmeldung} ende:BOOLEAN;{Variable zum Beenden des Programmes} wortpaar:t_wortpaar;{global definiertes Wortpaarfeld mit PASCAL-Strings} anfangsindex:ARRAY[1..20] OF BOOLEAN;{Hier wird die Index-Nummer all der Wortpaare hinterlegt, die mit gleichem Zeichen beginnen und damit zur Ermitt- lung von Korrespondenz verwendet werden können} testwort_x:PCHAR;{Ist der, zur Testung herangezogenene C-String für x-Worte - bei Korrespondenz gleich dem testwort_y!!!} testwort_y:PCHAR;{Ist der, zur Testung herangezogenene C-String für y-Worte - bei Korrespondenz gleich dem testwort_x!!!} cstring_x:PCHAR;{bekommt Zwischenwerte für die x_Worte während der Suche zugewiesen, PASCAL-Strings werden überführt in C} cstring_y:PCHAR;{bekommt Zwischenwerte für die y_Worte während der Suche zugewiesen, PASCAL-Strings werden überführt in C} wortpaarzaehler:WORD;{Zähler für die Wortpaare. Diese große Dimensionierung bedingt die Verwendung von C-Strings} index_lesen:BOOLEAN;{Entscheidet, ob Inizies gelesen oder geschrieben werden} index_loeschen:BOOLEAN;{Entscheidet, ob Inizies gelöscht werden oder nicht} indizies:ARRAY[1..index_dimension] OF BYTE;{Feld der Indizies, die zur eventuellen Korrespondenz führen} aktuelle_indexnummer:WORD;{Nummer des aktuell bearbeiteten Index, der Datentyp ist durch die theoretische Größe bestimmt.} aktueller_index:BYTE;{Inhalt des aktuellen Index} anfuegezaehler:WORD;{registriert die Anfügevorgänge mit dem Ziel, bei mißlungenem Versuch auf den nächsthöheren zuzugreifen} tiefenrgistratur:WORD;{verwaltet die aktuelle Anzahl von Anfügevorgängen} {*****************************************************************************************************} PROCEDURE seitenende(VAR f_abbruch:BOOLEAN); {Diese Prozedur übernimmt das Steuern eines Seitenendes, wenn Zwischenergebnisse oder andere Auswertungen vorgenommen werden sollen.} VAR l_taste:CHAR; BEGIN{begin procedure seitenende} GOTOXY(5,24); WRITE('>ESCAPE< >ENTER<'); REPEAT l_taste:=(READKEY); UNTIL l_taste IN[CHAR(13),CHAR(27)]; CLRSCR; IF l_taste=CHAR(27) THEN BEGIN{begin of then} f_abbruch:=TRUE;{Prozedur wird verlassen und Parameter "durchgereicht"} CLRSCR; EXIT; END;{end of then} END;{end of procedure seitenende} {*****************************************************************************************************} PROCEDURE init; {Diese Prozedur initialisiert das WINDOWS-Ausgabe-Fenster mit immer einheitlichen Startparametern (Größe des Fensters usw.) und der Fensterüberschrift. Verwendet werden die Einstellung für Standard VGA.} CONST l_fenstertitel='Post''sches Korrespondenzproblem'; BEGIN{begin procedure init} WINDOWORG.X:=0;{legt die Anfangskoordinaten in x-Richtung fest} WINDOWORG.Y:=0;{legt die Anfangskoordinaten in y-Richtung fest} WINDOWSIZE.X:=1024;{legt die Fenstergröße in x-Richtung fest} WINDOWSIZE.Y:=768;{legt die Fenstergröße in x-Richtung fest} STRCOPY(WINDOWTITLE,l_fenstertitel); INITWINCRT; END;{end of procedure init} {*****************************************************************************************************} PROCEDURE text_ausgabe(f_dateiname:STRING; VAR f_abbruch:BOOLEAN); {Prozedur zum seitenweisen Auflisten von Erklärungstexten. Diese Auflistung kann mit ESCAPE abgebrochen werden! Jede Seite umfaßt dabei 18 Zeilen.} VAR l_logischer_name:TEXT; zeichen:CHAR;{maximale Zeilenlänge!} fehler:BYTE;{nimmt den Fehlercode von IORESULT auf} l_zeilenzahl:BYTE;{Anzahl der aufgelisteten Zeilen} l_taste:CHAR; l_fehler:WORD;{lokaler Fehlerparameter} l_laufwerk:BYTE;{Laufwerksparameter} l_laufwerksbezeichner:STRING[5];{Laufwerksbuchstaben} l_pfadname:STRING[40];{Laufwerksbuchstaben} BEGIN{begin procedure text_ausgabe} CLRSCR; CHDIR('A:\'); ASSIGN(l_logischer_name,f_dateiname); {$I-} RESET(l_logischer_name); {$I+} fehler:=IORESULT; IF fehler<>0 THEN{Datei nicht gefunden} BEGIN{begin of then} CLRSCR; GETDIR(l_laufwerk,l_laufwerksbezeichner); CASE l_laufwerk OF 1:l_laufwerksbezeichner:='A';{erstes Diskettenlaufwerk} 2:l_laufwerksbezeichner:='B';{zweites Diskettenlaufwerk} 3:l_laufwerksbezeichner:='C';{erstes Festplattenlaufwerk} 4:l_laufwerksbezeichner:='D';{zweites Festplattenlaufwerk???} 5:l_laufwerksbezeichner:='E';{RAM-Floppy} ELSE BEGIN{begin of else} l_laufwerksbezeichner:='Laufwerk unbekannt' END;{end of else} END;{end of case} GOTOXY(2,10); WRITE('Die Datei ',f_dateiname,' wurde im Pfad ',l_laufwerksbezeichner,l_pfadname,' nicht gefunden!!!'); seitenende(f_abbruch);{call procedure seitenende} IF f_abbruch THEN BEGIN{begin of then} EXIT; END;{end of then} END{end of then} ELSE{Datei gefunden} BEGIN{begin of else} WHILE NOT EOF(l_logischer_name) DO BEGIN{begin of while} CLRSCR; WRITELN; WRITELN; WRITE(' '); l_zeilenzahl:=0; REPEAT READ(l_logischer_name,zeichen);{ein zeichen vom File wird gelesen} WRITE(zeichen); IF zeichen=#13{Line-Feed-Kodierung wird gesucht} THEN BEGIN{begin of then} l_zeilenzahl:=l_zeilenzahl+1;{Zeilenzähler um eins erhöht, wenn Zeilenende gelesen} WRITE(' '); END;{end of then} UNTIL (l_zeilenzahl=18)OR EOF(l_logischer_name); seitenende(f_abbruch);{call procedure seitenende} IF f_abbruch THEN BEGIN{begin of then} EXIT; END;{end of then} END;{end of else} END;{end of while} CLOSE(l_logischer_name);{Scließen der geöffneten Datei} CHDIR('A:\');{Verzeichnis auf Ausgang zurücksetzen, da sonst in der Programmlaufzeit Fehler auftreten können} END;{end of procedure text_ausgabe} {*****************************************************************************************************} PROCEDURE wortstamm_bilden; {Diese zentrale Prozedur im Programm zeichnet dafür verantwortlich, daß immer nur der Teil an Wortpaaren in den C-Strings steht, die einen gemeinsamen Wortstamm haben und damit Korrespondenz ermöglichen} VAR wortstammzaehler:WORD;{Lokale Schleifenvariable} i:BYTE; BEGIN{begin of procedure wortstamm_bilden} wortstammzaehler:=1; STRPCOPY(testwort_x,''#0);{Leersetzen des nullterminierten Strings} STRPCOPY(testwort_y,''#0);{Leersetzen des nullterminierten Strings} STRPCOPY(cstring_x,''#0);{Leersetzen des nullterminierten Strings} STRPCOPY(cstring_y,''#0);{Leersetzen des nullterminierten Strings} REPEAT{Die Strings, welche gleichen Wortstamm ergeben, werden gesucht} STRPCOPY(cstring_x,wortpaar[indizies[wortstammzaehler],1]);{Ein Wort x wird in den C-String geschrieben} STRPCOPY(cstring_y,wortpaar[indizies[wortstammzaehler],2]);{Ein Wort y wird in den C-String geschrieben} STRLCAT(testwort_x,cstring_x,c_dimension); STRLCAT(testwort_y,cstring_y,c_dimension); wortstammzaehler:=wortstammzaehler+1; UNTIL indizies[wortstammzaehler]=0; END;{end of procedure wortstamm_bilden} {*****************************************************************************************************} PROCEDURE wortpaare_einlesen(VAR f_abbruch:BOOLEAN); {Die Prozedur übernimmt die registratur des Feldes der einegebenen Wortpaare, welche zu anfangs leer gesetzt werden. ENTER-Taste wird abgeschnitten - Korrektur des Wortes ist mit BACK-Space möglich!} CONST l_dateiname:STRING[12]='INPUT.ANS'; eingabe:SET OF CHAR=['A'..'Z','a'..'z','0'..'9'];{repräsentiert den Wertevorrat des Alphabets an großen Buchstaben} VAR l_key:CHAR; go_on:CHAR; i:BYTE;{lokale Zahlvariable} BEGIN{begin procedure wortpaare_einlesen} wortpaarzaehler:=0; IF hilfstext THEN BEGIN{begin of then} text_ausgabe(l_dateiname,f_abbruch);{call procedure text_ausgabe} END;{end of then} FOR i:=1 TO 20 DO BEGIN{begin of for} wortpaar[i,1]:='';{Die Wortstrings für x-Worte werden leer gesetzt} wortpaar[i,2]:='';{Die Wortstrings für y-Worte werden leer gesetzt} END;{end of for} WHILE (NOT(go_on IN['n','N']))AND(wortpaarzaehler<=20) DO BEGIN{begin of while} CLRSCR; wortpaarzaehler:=wortpaarzaehler+1; WRITELN; WRITELN; WRITE(' Bitte die Zeichenfolge für die ',wortpaarzaehler,'. x-Kombination: '); REPEAT REPEAT l_key:=READKEY; UNTIL (l_key=CHR(13))OR(l_key IN eingabe)OR(l_key=CHR(8)); WRITE(l_key); IF l_key=#8 THEN{wurde die BACK-Space-Taste gedrückt?} BEGIN{begin of then} DELETE(wortpaar[wortpaarzaehler,1],LENGTH(wortpaar[wortpaarzaehler,1]),1);{letztes Zeichen löschen!} END;{end of then} IF (l_key<>CHR(13))AND(l_key<>CHR(8)) THEN BEGIN{begin of then} wortpaar[wortpaarzaehler,1]:=wortpaar[wortpaarzaehler,1]+l_key;{das neue Zeichen wird an das Wort angehangen} END;{end of then} UNTIL l_key=CHR(13); WRITELN; WRITE(' Bitte die Zeichenfolge für die ',wortpaarzaehler,'. y-Kombination: '); REPEAT REPEAT l_key:=READKEY; UNTIL (l_key=CHR(13))OR(l_key IN eingabe)OR(l_key=CHR(8)); WRITE(l_key); IF l_key=#8 THEN{wurde die BACK-SPACE-Taste gedrückt?} BEGIN{begin of then} DELETE(wortpaar[wortpaarzaehler,2],LENGTH(wortpaar[wortpaarzaehler,2]),1);{letztes Zeichen löschen!} END;{end of then} IF (l_key<>CHR(13))AND(l_key<>CHR(8)) THEN BEGIN{begin of then} wortpaar[wortpaarzaehler,2]:=wortpaar[wortpaarzaehler,2]+l_key; END;{end of then} UNTIL l_key=CHR(13); IF wortpaarzaehler<20 THEN BEGIN{begin of then} GOTOXY(15,20); WRITELN('Noch maximal ',20-wortpaarzaehler,' Wortpaare können eingegeben werden!'); GOTOXY(5,24); WRITE('>ESCAPE< Folgt eine weiteres Wortpaar? (Y/N):'); REPEAT go_on:=READKEY; UNTIL (go_on IN['n','N','y','Y',CHAR(27)]); IF go_on=CHAR(27) THEN BEGIN{begin of then} f_abbruch:=TRUE; CLRSCR; EXIT; END;{end of then} END;{end of then} END;{end of while} END;{end of procedure wortpaare_einlesen} {*****************************************************************************************************} PROCEDURE wortpaar_anzeigen(VAR f_richtige_eingabe,f_abbruch:BOOLEAN); {Auf Nutzeranforderung hin werden die eingegebenen Wortpaare nochmals angezeigt. Der Nutzer hat damit nach der Anzeige der Liste besteht die Möglichkeit, Korrekturen in der Eingabe vorzunehmen.} VAR i:BYTE;{Schleifenzahler} l_taste:CHAR;{Lokale Tastaturverwaltung} BEGIN{begin procedure wortpaare_anzeigen} CLRSCR; WRITELN; WRITELN; FOR i:=1 TO wortpaarzaehler DO BEGIN{begin of for} WRITELN(' Ihr ',i,'. Wortpaar: ',wortpaar[i,1],' und ',wortpaar[i,2]); END;{end of for} WRITELN; WRITE(' >ESCAPE< Eingabe OK? (Y/N)'); REPEAT l_taste:=(READKEY); UNTIL l_taste IN[CHAR(78),CHAR(89),CHAR(27),CHAR(110),CHAR(121)]; IF l_taste=CHAR(27) THEN BEGIN{begin of then} f_abbruch:=TRUE;{Prozedur wird verlassen und Parameter "durchgereicht"} CLRSCR; EXIT; END{end of then} ELSE BEGIN{begin of else} IF (l_taste=CHAR('y'))OR(l_taste=CHAR('Y')){Eingabe geht in Ordnung} THEN BEGIN{begin of then} f_richtige_eingabe:=TRUE; END;{end of then} END;{end of else} END;{end of procedure wortpaare_anzeigen} {*****************************************************************************************************} PROCEDURE indexverwaltung(f_control,f_index_lesen,f_index_loeschen:BOOLEAN; VAR f_aktuelle_indexnummer:WORD; f_aktueller_index:BYTE; VAR f_abbruch:BOOLEAN); VAR zeilenzaehler:BYTE;{Lokaler Schleifenzähler zur Anzeige registrierter Indizies} l_taste:CHAR;{Lokale Tastaturabfragevariable} {Diese Prozedur verwaltet ein Feld der Indizies der Worte, die zur Korrespondenzermittlung herangezogen werden. Dieses Feld kann bei Ermittlung geschrieben, und wenn mit einer Wortfolge keine Gleichheit des Wortstammes gefunden wurde, kann der letzte Index aus diesem Feld gestrichen werden. Zum Abschluß kann bei gefundener oder unwahrscheinlicher Korrespondenz dieses Feld ausgewertet (angezeigt) werden. Was die Prozedur aktuell ausführt, wird durch die Übergabeparameter f_index_lesen sowie f_index_loeschen entschieden} BEGIN{begin of procedure indexverwaltung} IF (f_index_lesen)AND(NOT(f_index_loeschen)) THEN{dann wird das Indexfeld ausgelesen und angezeigt!} BEGIN{begin of then1} CLRSCR; WRITELN; f_aktuelle_indexnummer:=1; REPEAT REPEAT WRITELN(' Der ',f_aktuelle_indexnummer,'. Index war das ',indizies[f_aktuelle_indexnummer],'. Wort aus x und y!'); f_aktuelle_indexnummer:=f_aktuelle_indexnummer+1;{Aufruf nächster Index, welcher im Inhalt ungleich Null ist!} UNTIL (zeilenzaehler=22)OR(indizies[f_aktuelle_indexnummer]=0); seitenende(f_abbruch);{call procedure seitenende} IF f_abbruch THEN BEGIN{begin of then} EXIT; END;{end of then} UNTIL indizies[f_aktuelle_indexnummer]=0; CLRSCR; END;{end of then} IF (NOT(f_index_lesen))AND(f_index_loeschen){dann wird entweder geschrieben oder gelöscht und korrigiert!} THEN{dann wird der letzte Index zurückgesetzt und damit nachfolgend die Testworte korrigiert!} BEGIN{begin of then} indizies[f_aktuelle_indexnummer]:=0;{Der letzte angefügte Index wird gestrichen} f_aktuelle_indexnummer:=f_aktuelle_indexnummer-2;{Indexfeld um zwei zurückgesetzt} wortstamm_bilden;{call procedure wortstamm_bilden} END;{end of then} IF (NOT(f_index_lesen))AND(NOT(f_index_loeschen)){das Indexfeld wird mit aktuellen Parametern gesetzt} THEN BEGIN{begin of then} IF f_aktuelle_indexnummer<=36166 THEN BEGIN{begin of then} indizies[f_aktuelle_indexnummer]:=f_aktueller_index;{Der aktuelle Index wird in das Feld eingetragen} f_aktuelle_indexnummer:=f_aktuelle_indexnummer+1;{nach Verarbeitung des aktuellen Index Nummer erhöht um eins} END;{end of then} END;{end of then} END;{end of procedure indexverwaltung} {*****************************************************************************************************} PROCEDURE gehts_denn_ueberhaupt(VAR f_abbruch,f_geht:BOOLEAN;f_control:BOOLEAN); {Diese Prozedure stellt fest, ob Korrespndenz generell möglich ist dies ist nur dann der Fall, wenn es mindestens ein Wort x sowie ein Wort y in einem Wortpaar gibt, die mit dem gleichen Zeichen des definierten Alphabets beginnen. Außerdem wird die Position innerhalb der Wortpaarmenge festgetellt, wo dies zutrifft. Die Menge aller Indizies wird in einem BOOLEAN-Feld registriert, welches in der Dimension gleich 20 ist.} VAR l_test_x:STRING[stringdimension];{Vergleichsvariable zur Feststellung, ob zwei Wortpaare mit gleichem Zeichen beginnen} l_test_y:STRING[stringdimension];{Vergleichsvariable zur Feststellung, ob zwei Wortpaare mit gleichem Zeichen beginnen} l_taste:CHAR;{Lokale Tastaturabfragevariable} BEGIN{begin of procedure gehts_denn_ueberhaupt} FOR aktueller_index:=1 TO wortpaarzaehler DO BEGIN{begin of for} l_test_x:=COPY(wortpaar[aktueller_index,1],1,1);{das erste Zeichen des Wortes x wird abgschnitten} l_test_y:=COPY(wortpaar[aktueller_index,2],1,1);{das erste Zeichen des Wortes y wird abgschnitten} IF l_test_x=l_test_y THEN BEGIN{begin of then} f_geht:=TRUE;{Korrespondenz ist prinzipiell möglich} anfangsindex[aktueller_index]:=TRUE;{Das Feld der Anfangsindizies wird geschrieben} CLRSCR; GOTOXY(10,10); WRITELN(aktueller_index,'. Wort x und ',aktueller_index,'. Wort y beginnen mit gleichem Zeichen!'); GOTOXY(3,12); WRITELN('Gemeinsames Zeichen ist: ',l_test_x,' ! Damit ist Korespondenz generell möglich!!!'); seitenende(f_abbruch);{call procedure seitenende} IF f_abbruch THEN BEGIN{begin of then} EXIT; END;{end of then} END;{end of then} END;{end of for} END;{end of procedure gehts_denn_ueberhaupt} {*****************************************************************************************************} PROCEDURE wortvergleich(f_control:BOOLEAN; VAR f_gleich,f_abbruch:BOOLEAN; f_testwort_x,f_testwort_y,f_cstring_x,f_cstring_y:PCHAR); {Diese Prozedur ermittelt zuerst die aktuelle Wortlänge beider C-Strings, um anschließend den längeren um die Länge des kürzeren abzuschneiden und festzustellen, ob diese Teile gleich sind. Wenn dies nicht der Fall ist, brauchen keine weiteren Testsrings angehangen zu werden - es gibt dann keine Korrespondenz. Die Prozedur anfuegen wird nicht weiter ausgeführt, was die Laufzeit des Programmes erheblich verkürzt.} VAR laenge_des_kuerzeren_strings:WORD;{lokale Variablen zur Feststellung der aktuellen Wortlänge} l_taste:CHAR;{Lokale Tastatursteuerungsvariable} BEGIN{begin of procedure wortvergleich} f_gleich:=FALSE;{Rücksetzen der Identitätsvariablen} STRPCOPY(f_cstring_x,''#0);{Leersetzen des nullterminierten lokalen Strings} STRPCOPY(f_cstring_y,''#0);{Leersetzen des nullterminierten lokalen Strings} IF STRLEN(f_testwort_x)>STRLEN(f_testwort_y){Wort x ist länger als Wort y} THEN BEGIN{begin of then} laenge_des_kuerzeren_strings:=STRLEN(f_testwort_y); STRLCAT(f_cstring_x,f_testwort_x,laenge_des_kuerzeren_strings); STRLCAT(f_cstring_y,f_testwort_y,laenge_des_kuerzeren_strings); END{end of then} ELSE BEGIN{begin of else1} IF STRLEN(f_testwort_x)<STRLEN(f_testwort_y){Wort y ist länger als Wort x} THEN BEGIN{begin of then2} laenge_des_kuerzeren_strings:=STRLEN(f_testwort_x); STRLCAT(f_cstring_x,f_testwort_x,laenge_des_kuerzeren_strings); STRLCAT(f_cstring_y,f_testwort_y,laenge_des_kuerzeren_strings); END{end of then2} ELSE{wenn die Worte gleichlang sind} BEGIN{begin of else2} laenge_des_kuerzeren_strings:=STRLEN(f_testwort_y); STRLCAT(f_cstring_x,f_testwort_x,laenge_des_kuerzeren_strings); STRLCAT(f_cstring_y,f_testwort_y,laenge_des_kuerzeren_strings); END;{end of else2} END;{end of else1} IF STRCOMP(f_cstring_x,f_cstring_y)=0{Testen der "Hilfsworte" auf Gleichheit} THEN BEGIN{begin of then} f_gleich:=TRUE; END;{end of then} IF (f_gleich)AND(f_control) THEN BEGIN{begin of then1} GOTOXY(5,4); WRITE('Die Wortstämme fallen gleich aus - es geht also weiter!'); GOTOXY(5,6); WRITE('Der gemeinsame Wortstamm lautet:'); GOTOXY(5,8); WRITE(f_cstring_x); seitenende(f_abbruch);{call procedure seitenende} IF f_abbruch THEN BEGIN{begin of then2} EXIT; END;{end of then2} END;{end of then1} IF NOT(f_gleich)AND(f_control) THEN BEGIN{begin of then1} GOTOXY(5,4); WRITELN('Die Wortstämme fallen nicht gleich aus - es geht also nicht weiter!'); GOTOXY(5,6); WRITELN('Die Wortstämme: '); GOTOXY(5,8); WRITE(f_cstring_x); GOTOXY(5,10); WRITE(' und'); GOTOXY(5,12); WRITE(f_cstring_y); seitenende(f_abbruch);{call procedure seitenende} IF f_abbruch THEN BEGIN{begin of then2} EXIT; END;{end of then2} END;{end of then1} END;{end of procedure wortvergleich} {*****************************************************************************************************} PROCEDURE anhaengen(f_i,f_j:BYTE; f_control:BOOLEAN; VAR f_exitcode,f_abbruch:BOOLEAN); {Diese Prozedur fügt eine weitere Zeichenkette aus dem Wortvorrat von x und y an die Testworte an, sofern der Wortstamm dabei gleich bleibt.} VAR l_gleich:BOOLEAN;{Gleichheitsvariable für die Testworte} l_taste:CHAR;{Lokale Tastatursteuerungsvariable} BEGIN{begin of procedure anhaengen} l_gleich:=FALSE;{Worte werden für den Wortvergleich ungleich gesetzt} STRPCOPY(cstring_x,''#0);{Leersetzen des nullterminierten lokalen Strings} STRPCOPY(cstring_y,''#0);{Leersetzen des nullterminierten lokalen Strings} STRPCOPY(cstring_x,wortpaar[f_j,1]); STRPCOPY(cstring_y,wortpaar[f_j,2]); STRLCAT(testwort_x,cstring_x,c_dimension); STRLCAT(testwort_y,cstring_y,c_dimension); index_lesen:=FALSE; index_loeschen:=FALSE; indexverwaltung(f_control,index_lesen,index_loeschen,aktuelle_indexnummer,f_j,f_abbruch);{callprocedure indexverwaltung} IF f_control THEN BEGIN{begin of then} GOTOXY(10,2); WRITELN('Das ist der ',f_i,'. Versuch, Worte anzufügen!'); GOTOXY(10,5); WRITELN('Das ',f_j,'. Wortpaar wird nun angefügt!'); GOTOXY(10,10); WRITELN('Das ist für x das Wort: ',cstring_x); GOTOXY(10,12); WRITELN('Und damit ergibt sich als augenblicklicher Inhalt von Testwort x: '); GOTOXY(10,14); WRITELN(testwort_x); GOTOXY(10,16); WRITELN('Für das Wort y ist das: ',cstring_y); GOTOXY(10,18); WRITELN('und damit als augenblicklicher Inhalt von Testwort y: '); GOTOXY(10,20); WRITELN(testwort_y); GOTOXY(5,24); WRITE('>ESCAPE< >ENTER<'); REPEAT l_taste:=(READKEY); UNTIL l_taste IN[CHAR(13),CHAR(27)]; IF l_taste=CHAR(27) THEN BEGIN{begin of then2} f_abbruch:=TRUE;{Prozedur wird verlassen und Parameter "durchgereicht"} CLRSCR; EXIT; END;{end of then2} CLRSCR; END;{end of then} wortvergleich(f_control,l_gleich,f_abbruch,testwort_x,testwort_y,cstring_x,cstring_y);{call procedure wortvergleich} IF NOT(l_gleich) THEN{Die Wortstämme der testworte sind dann nicht mehr gleich und die Anfügeprozedur muß abgebrochen werden} BEGIN{begin of then} f_abbruch:=FALSE;{Prozedur wird verlassen und Parameter und mit dem Wort des nachfolgenden Index wird erneut gesucht} f_exitcode:=TRUE;{Erkennungsparameter, daß die Testworte nicht mehr übereinstimmen} EXIT; END;{end of then} END;{end of procedure anhaengen} {*****************************************************************************************************} PROCEDURE heureka(f_ermittlungstiefe:WORD; VAR f_exitcode,f_abbruch:BOOLEAN; f_control:BOOLEAN); {Wenn eine generelle Korrespondenz möglich ist, wird sie durch diese Prozedur einschließlich der Anzeige des übereinstimmenden Wortes, ermittelt.} CONST l_dateiname:STRING[12]='HEUREKA.ANS'; VAR i:BYTE;{äußerer Schleifenzähler} l_taste:CHAR;{Lokale Tastatursteuerungsvariable} BEGIN{begin of procedure heureka} IF hilfstext THEN{Hilfetextausgabe} BEGIN{begin of then} text_ausgabe(l_dateiname,f_abbruch);{call procedure text_ausgabe} END;{end of then} IF f_control THEN BEGIN{begin of then1} CLRSCR; GOTOXY(10,5); WRITE(' Begonnen wird mit dem Wortpaar: ',testwort_x,' und ',testwort_y,'!'); seitenende(f_abbruch);{call procedure seitenende} IF f_abbruch THEN BEGIN{begin of then2} EXIT; END;{end of then2} END;{end of then1} anfuegezaehler:=1; FOR i:=1 TO f_ermittlungstiefe DO BEGIN{begin of for} WHILE (anfuegezaehler<f_ermittlungstiefe)AND(STRLEN(testwort_x)/5<=c_dimension)AND(STRLEN(testwort_y)/5<=c_dimension) DO BEGIN{begin of while} anhaengen(i,anfuegezaehler,f_control,f_exitcode,f_abbruch);{call procedure anhaengen} anfuegezaehler:=anfuegezaehler+1; IF f_abbruch THEN BEGIN{begin of then} CLRSCR; EXIT; END;{end of then} IF f_exitcode THEN BEGIN{begin of then} EXIT; END;{end of then} IF STRCOMP(testwort_x,testwort_y)=0{einlesen auf Gleichheit} THEN BEGIN{begin of then1} CLRSCR; GOTOXY(5,10); WRITE('Heureka - Korrespondenz mit: '); GOTOXY(5,12); WRITE(testwort_x); GOTOXY(5,14); WRITE('gefunden!!!'); seitenende(f_abbruch);{call procedure seitenende} IF f_abbruch THEN BEGIN{begin of then} EXIT; END;{end of then} CLRSCR; GOTOXY(5,10); WRITE('Soll die Liste der Indizies angezeigt werden? (Y/N): '); REPEAT l_taste:=(READKEY); UNTIL l_taste IN['y','Y','n','N']; IF UPCASE(l_taste)='Y' THEN BEGIN{begin of then} index_lesen:=TRUE;{Indizies sollen ausgelesen werden} index_loeschen:=FALSE;{Indizies werden nicht zur Korrektur aufgerufen} indexverwaltung(f_control,index_lesen,index_loeschen,aktuelle_indexnummer,aktueller_index,f_abbruch); {call procedure indexverwaltung} END;{end of then} CLRSCR; IF f_abbruch THEN BEGIN{begin of then} CLRSCR; EXIT; END;{end of then} END;{end of then} END;{end of while} END;{end of for} END;{end of procedure heureka} {*****************************************************************************************************} PROCEDURE pruefen(VAR f_abbruch:BOOLEAN); {diese Prozedur steuert nach dem Einlesen des Wortpaarfeldes den gesamten Ablauf zur Ermittlung von Korrespondenz - findet dies aber nur dann selbst, wenn das erste gemeinsame Wort aus x und y übereinstimmen! Ansonsten ruft sie die Prozeduren gehts_denn_ueberhaupt und hereka, welche dann die eigentliche Suche übernehmen} CONST l_dateiname:STRING[12]='SUCHEN.ANS'; VAR i:BYTE;{Schleifenzähler} j:WORD;{Schleifenzähler} ermittlungstiefe:WORD; l_geht:BOOLEAN;{Variable zur Registratur der Möglichkeit von Korrespondenz} l_gleich:BOOLEAN;{Testet auf Gleichheit der Strings in verschieden langen Worten} exitcode:BOOLEAN;{Variable zum Registrieren des vorzeitigen Verlassens der Prozedur anhaengen} control:BOOLEAN;{Steuerungsvariable zur Anzeige von Zwischenergebnissen} l_ja_nein:CHAR;{Abfragevariable} l_taste:CHAR;{Lokale Tastatursteuerungsvariable} BEGIN{begin of procedure pruefen} control:=FALSE;{Anzeigesteuerung wird falsch gesetzt} exitcode:=FALSE; l_gleich:=FALSE;{Wortgleichheit wird falsch gesetzt} l_geht:=FALSE;{Korrespondenzvariable wird falsch gesetzt} FOR i:=1 TO 20 DO BEGIN{begin of for} anfangsindex[i]:=FALSE;{Anfangsindexfeld Falsch setzen} END;{end of for} IF hilfstext THEN BEGIN{begin of then} text_ausgabe(l_dateiname,f_abbruch);{call procedure text_ausgabe} END;{end of then} CLRSCR; GOTOXY(2,10); WRITE('Sollen die Zwischenergebnisse beim Wortanfügen mit angezeigt werden? (Y/N): '); REPEAT l_ja_nein:=READKEY; UNTIL l_ja_nein IN['n','N','y','Y']; IF UPCASE(l_ja_nein)='Y' THEN BEGIN{begin of then} control:=TRUE;{Zwischenwerte werden angezeigt} END;{end of then} gehts_denn_ueberhaupt(f_abbruch,l_geht,control){call procedure gehts_denn_ueberhaupt}; IF f_abbruch THEN BEGIN{begin of then} CLRSCR; EXIT; END;{end of then} IF (l_geht) THEN BEGIN{begin of then} IF control THEN BEGIN{begin of then} REPEAT CLRSCR; GOTOXY(2,12); WRITE('Ermittlungstiefe (max. 50 bei Anzeige der Zwischenwerte): '); READLN(ermittlungstiefe); CLRSCR; UNTIL ermittlungstiefe<=50; END{end of then} ELSE BEGIN{begin of else} ermittlungstiefe:=65535; END;{end of else} FOR i:=1 TO wortpaarzaehler DO{Absuchen des gesamten Wortpaarfeldes auf gleiches Anfangszeichen} BEGIN{begin of for} IF anfangsindex[i]{Suchen des Index's der Worte, die mit gleichem Zeichen beginnen} THEN BEGIN{begin of then} FOR j:=1 TO index_dimension DO BEGIN{begin of for} indizies[j]:=0;{Leersetzen des Indexfeldes vor jedem Programmlauf} END;{end of for} aktuelle_indexnummer:=1; index_lesen:=FALSE; index_loeschen:=FALSE; indexverwaltung(control,index_lesen,index_loeschen,aktuelle_indexnummer,i,f_abbruch);{call procedure indexverwaltung} wortstamm_bilden;{call procedure wortstamm_bilden} IF STRCOMP(testwort_x,testwort_y)=0{wenn beide C-Strings schon gleich sind} THEN{Testworte mit gleichem Startzeichen sind auch schon insgesamt gleich} BEGIN{begin of then2} WRITELN(' Korrespondenz schon gefunden - das gleiche Wort lautet ',testwort_x); seitenende(f_abbruch);{call procedure seitenende} IF f_abbruch THEN BEGIN{begin of then} EXIT; END;{end of then} END;{end of then} tiefenrgistratur:=1; WHILE tiefenrgistratur<=ermittlungstiefe DO BEGIN{begin of while} heureka(ermittlungstiefe,exitcode,f_abbruch,control);{call procedure heureka} IF f_abbruch THEN BEGIN{begin of then} EXIT; END;{end of then} IF exitcode THEN BEGIN{begin of then} IF control THEN BEGIN{begin of then} CLRSCR; GOTOXY(10,8); WRITE('Bisher keine Korrespondenz gefunden - jedoch nicht ausgeschlossen!'); GOTOXY(5,24); WRITE('>ESCAPE< >ENTER< zur Forsetzung der Suche'); REPEAT l_taste:=(READKEY); UNTIL l_taste IN[CHAR(13),CHAR(27)]; IF l_taste=CHAR(27) THEN{Die Suche wird abgebrochen} BEGIN{begin of then} f_abbruch:=TRUE;{Prozedur wird verlassen und Parameter "durchgereicht"} CLRSCR; EXIT; END;{end of then} END{end of then} ELSE{Die Suche soll mit korrigiertem Wort fortgesetzt werden} BEGIN{begin of else} exitcode:=FALSE;{Registraturvariable zurücksetzen} f_abbruch:=FALSE;{Prozedur wird nicht verlassen} index_lesen:=FALSE;{Index wird geschrieben} index_loeschen:=TRUE;{IIndex wird im Sinne einer Rückwärtskorrektur geschrieben} indexverwaltung(control,index_lesen,index_loeschen,aktuelle_indexnummer,aktuelle_indexnummer,f_abbruch); {callprocedure indexverwaltung} wortstamm_bilden;{call procedure wortstamm_bilden} heureka(ermittlungstiefe,exitcode,f_abbruch,control);{call procedure heureka} tiefenrgistratur:=tiefenrgistratur+1; END;{end of else} END;{end of then} END;{end of while} END;{end of then} END;{end of for} END{end of then} ELSE{Keine Korrespondenz möglich} BEGIN{begin of else} CLRSCR; GOTOXY(10,10); WRITELN('Keine Korespondenz möglich, da keines der Worte'); GOTOXY(10,12); WRITELN('aus x und y mit gleichem Zeichen beginnen!!!'); seitenende(f_abbruch);{call procedure seitenende} IF f_abbruch THEN BEGIN{begin of then} EXIT; END;{end of then} END;{end of else} END;{end of procedure pruefen} {*****************************************************************************************************} PROCEDURE einlesen_und_organisieren(VAR f_abbruch:BOOLEAN); {Diese Prozedur organisiert durch Aufruf entsprechender Prozeduren das Einlesen der Wortfelder x und y, deren Anzeige und Prüfung auf Korrespondenz durch den Aufruf weiterer Prozeduren} VAR i:BYTE;{Schleifenzähler} l_ja_nein:CHAR;{Abfragevariable} l_zaehler:BYTE;{Zähler für die Menge der Wörter} l_richtige_eingabe:BOOLEAN;{Verwaltet die richtige Eingabe von Wortpaarkombinationen} BEGIN{begin procedure einlesen} REPEAT l_richtige_eingabe:=FALSE;{Eingabe wird falsch angenommen} wortpaare_einlesen(f_abbruch);{call procedure wortpaar_einlesen} IF f_abbruch THEN BEGIN{begin of then} CLRSCR; EXIT;{ESCAPE-Tatse wurde beim Wortpaareinlesen gedrückt} END;{end of then} CLRSCR; GOTOXY(15,20); WRITE('Sollen die Wortpaare nochmals angezeigt werden? (Y/N)'); REPEAT l_ja_nein:=READKEY; UNTIL l_ja_nein IN['n','N','y','Y']; IF UPCASE(l_ja_nein)='Y' THEN BEGIN{begin of then1} wortpaar_anzeigen(l_richtige_eingabe,f_abbruch);{call procedure wortpaare_anzeigen} IF f_abbruch THEN BEGIN{begin of then2} CLRSCR; EXIT; END;{end of then2} END{end of then1} ELSE BEGIN{begin of else} l_richtige_eingabe:=TRUE;{Eingabe ist richtig} END;{end of else} UNTIL l_richtige_eingabe; pruefen(f_abbruch);{call procedure pruefen} END;{end of procedure einlesen} {*****************************************************************************************************} PROCEDURE main_menu(VAR f_abbruch:BOOLEAN); CONST l_dateiname:STRING[12]='POST.ANS'; VAR zweig:CHAR;{Verzweigungsvariable} zahl:WORD; taste:CHAR;{Variable zur Tastaturabfrage} l_taste:CHAR;{Lokale Tastatursteuerungsvariable} BEGIN{begin of procedure main_menu} STRPCOPY(testwort_x,''#0);{Leersetzen des nullterminierten Strings testwort_x} STRPCOPY(testwort_y,''#0);{Leersetzen des nullterminierten Strings testwort_y} WRITELN; WRITELN; WRITELN(' Diese Programm ermittelt von eingegebenen Wortpaaren die'); WRITELN(' generelle Möglichkeit, die ermittelten Worte sowie deren'); WRITELN(' Indizies bei Vorliegen von Korrespondenz. Beachten Sie bitte'); WRITELN(' die Hinweise für Eingaben sowie deren Korrektur. Die Anzeige'); WRITELN(' der einzelenen Ermittlungsstufen von Korrepondenz sollte'); WRITELN(' bis zu einer maximalen Tiefe von 50 aufgerufen werden,'); WRITELN(' da ansonsten die Laufzeit bis zum Ende erheblich, und'); WRITELN(' die Übersichtlichkeit stark eingeschränkt werden kann.'); WRITELN(' Anliegen des Programmes ist es nicht, jede Korrespondenz'); WRITELN(' aus einer Menge von Wortpaaren zu finden. Ergibt sich eine solche'); WRITELN(' schon mit dem ersten Wortpaar, steigt das Programm aus, es'); WRITELN(' sucht also nach der generellen Möglichkeit, nicht nach allen'); WRITELN(' denkbaren Kombinationen für eine Wortpaarfolge.'); WRITELN(' Wird im folgenden Programmablauf von einem Wortstamm gesprochen,'); WRITELN(' so ist der Gehalt an Worten gemeint, der nach einer Anfügeoperation.'); WRITELN(' das jeweils kürzere in der Referenz des längeren abbildet (Das'); WRITELN(' kürzere Wort ist im längeren enthalten!).'); GOTOXY(3,24); WRITE('>ESCAPE< Erklärungstext? (Y/N): '); REPEAT l_taste:=READKEY; UNTIL l_taste IN['n','N','y','Y',CHAR(27)]; IF UPCASE(l_taste)='Y' THEN BEGIN{begin of then} hilfstext:=TRUE; END{end of then} ELSE BEGIN{begin of else} hilfstext:=FALSE; END;{end of else} IF l_taste=CHAR(27) THEN BEGIN{begin of then2} f_abbruch:=TRUE;{Prozedur wird verlassen und Parameter "durchgereicht"} CLRSCR; EXIT; END;{end of then2} CLRSCR; WRITELN; WRITELN(' Informationen zum Post''schen Koerrespondenzproblem .................. 1'); WRITELN(' Feststelung, ob Korrespondenz vorliegt .............................. 2'); WRITELN(' ENDE .................................................................3'); WRITELN; WRITE(' Sie wünschen?: '); REPEAT{REPEAT for right key} zweig:=READKEY; UNTIL zweig IN ['1'..'3']; CASE zweig OF '1': BEGIN{begin of brach '1'} text_ausgabe(l_dateiname,f_abbruch);{call procedure text_ausgabe} IF f_abbruch THEN BEGIN{begin of then} CLRSCR; EXIT; END;{end of then} CLRSCR; GOTOXY(10,10); WRITELN('Wünschen Sie, mit dem Programm zu arbeiten? (Y/N): '); REPEAT l_taste:=READKEY; UNTIL l_taste IN['n','N','y','Y']; IF UPCASE(l_taste)='Y' THEN BEGIN{begin of then} einlesen_und_organisieren(f_abbruch);{call procedure einlesen_und_organisieren} END{end of then} ELSE{das Programm wird verlassen} BEGIN{begin of else} f_abbruch:=TRUE; CLRSCR; EXIT; END;{end of else} END;{end of brach '1'} '2':einlesen_und_organisieren(f_abbruch);{call procedure einlesen_und_organisieren} END;{end of case} IF zweig='3' THEN BEGIN{begin of then} CLRSCR; f_abbruch:=TRUE; EXIT; END;{end of then} END;{end of procedure main_menu} {*****************************************************************************************************} BEGIN{begin main routine} init;{call procedure} STRNEW(testwort_x);{Kreieren des nullterminierten Strings testwort_x} STRNEW(testwort_y);{Kreieren des nullterminierten Strings testwort_y} GETMEM(testwort_x,c_dimension);{Dimensionieren des C-Strings testwort_x} GETMEM(testwort_y,c_dimension);{Dimensionieren des C-Strings testwort_y} STRNEW(cstring_x);{Kreieren des nullterminierten Strings cstring_x} STRNEW(cstring_y);{Kreieren des nullterminierten Strings cstring_y} GETMEM(cstring_x,c_dimension);{Dimensionieren des C-Strings cstring_x} GETMEM(cstring_y,c_dimension);{Dimensionieren des C-Strings cstring_y} anfuegezaehler:=1;{damit wird mit der ersten Wortpaargruppe nach Korrespondnez gesucht} REPEAT CLRSCR; wortpaarzaehler:=0;{noch wurde kein Wort im aktuellen Programmlauf erfaßt} abbruch:=FALSE;{Abbruchvariable für wiederholten Programmlauf zurücksetzen} main_menu(abbruch);{call procedure main_menu} IF abbruch THEN BEGIN{begin of then} wiederholung:='N';{Programmwiederholungsvariable wird vorerst NEIN gesetzt und damit nicht wiederholt} nochmal:='n'; END{end of then} ELSE BEGIN{begin of else} REPEAT CLRSCR; GOTOXY(13,15); WRITE('Wiederholung des Programmes gewünscht? (Y/N): '); nochmal:=READKEY; UNTIL nochmal IN['n','N','y','Y']; END;{end of else} IF (nochmal='n')OR(nochmal='N') THEN BEGIN{begin of then} anfuegezaehler:=1;{damit wird mit der ersten Wortpaargruppe nach Korrespondnez gesucht} CLRSCR; GOTOXY(10,10); WRITE('Das Programm soll abgebrochen werden? (Y/N)'); REPEAT wiederholung:=READKEY; UNTIL wiederholung IN['n','N','y','Y'] END;{end of then} UNTIL (wiederholung=('Y'))OR(wiederholung=('y')); DISPOSE(testwort_x);{Löschen des C-Strings testwort_x} DISPOSE(testwort_y);{Löschen des C-Strings testwort_y} DISPOSE(cstring_x);{Löschen des C-Strings cstring_x} DISPOSE(cstring_y);{Löschen des C-Strings cstring_y} DONEWINCRT; END.{end of program} {*****************************************************************************************************} { Copyrights by F. Rost Stand 27.10.1994 } {*****************************************************************************************************} |
|
| Dokumentation zum Programm |
| 5. Zusammenfassung |
|
|
|
|
|
|
| der Lösungsalgorithmus der Türme von Hanoi ist nicht komplex, jedoch schon mit geringer Anzahl n mächtig - er ist n-polinomial | |
| es muss also insgesamt hoher Lösungsaufwand betrieben werden - auch ein Computer wird für n=1000 in absehbarer Zeit keine Lösung bringen | |
| 6. Weiterführende Literatur |
|
|
|
|
|
|
| der Lösungsalgorithmus der Türme von Hanoi ist nicht komplex, jedoch schon mit geringer Anzahl n mächtig | |
| es muss also insgesamt hoher Lösungsaufwand betrieben werden - auch ein Computer wird für n=1000 in absehbarer Zeit keine Lösung bringen | |
| 7. Links zum Thema |
|
|
|
|
|
Viele gibt es - die meisten sind JAVA-basierte Spiele, um den erkannten Lösungsalgorithmus nach zu vollziehen. Wie gesagt, wenn Du vor hast, das Spiel noch am laufenden Tag zu beenden, verwende keine Scheibenzahl größer 20 - das ist dann schon nicht mehr zu schaffen. |
| http://www.blinde-kuh.de/spiele/hanoi/ | |
| http://www.cut-the-knot.org/recurrence/hanoi.shtml |
| 8. Verwandte Themen |
|
|
|
|
|
Das Vorangestellte hilft wirtschaften für genau dieses Problem (allerdings ohne Beachtung der Worst-Case-Strategien wird man auch nicht erfolgreich Software entwickeln und/oder informatische Projekte realisieren können). Deshalb nunmehr das, was wirklich Arbeiten hilft. | |||||||||||||||||||||
|
||||||||||||||||||||||
|
||||||||||||||||||||||
|
|
zur Hauptseite |
© Samuel-von-Pufendorf-Gymnasium Flöha | © Frank Rost im März 1994 |
|
... dieser Text wurde nach den Regeln irgendeiner Rechtschreibreform verfasst - ich hab' irgendwann einmal beschlossen, an diesem Zirkus nicht mehr teilzunehmen ;-) „Dieses Land braucht eine Steuerreform, dieses Land braucht eine Rentenreform - wir schreiben Schiffahrt mit drei „f“!“ Diddi Hallervorden, dt. Komiker und Kabarettist |
|
Diese Seite wurde ohne Zusatz irgendwelcher Konversationsstoffe erstellt ;-) |
![]()


{kind=link}