| 1.3. Theorie der Prozessrechentechnik |
|
|
Letztmalig dran rumgefummelt: 12.10.12 19:17:44 |
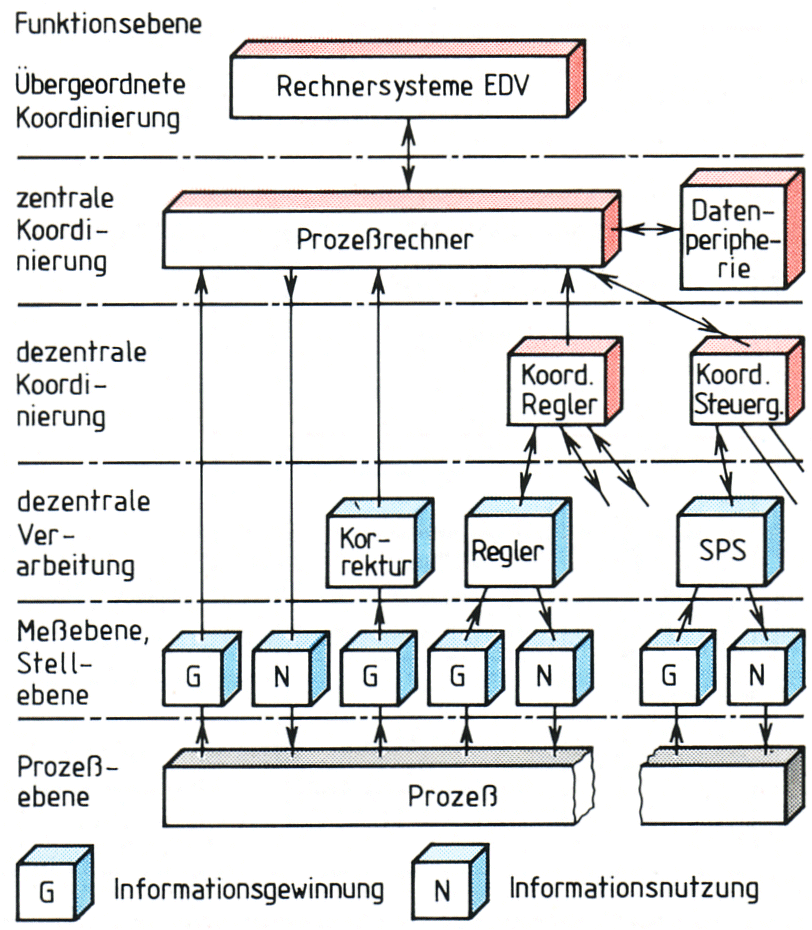
| Prozessrechner müssen Steuerungsaufgaben in Echtzeit übernehmen. Dafür muss ihre Hardware vorbereitet, jedoch auch ihre Software darauf eingestellt sein. Zudem arbeiten heute Mikrorechner im Verbund - sie sind also vernetzt - und periphere Aufgaben werden auch von peripheren Controllern übernommen. | |||||||
|
+++ PROZESSRECHNER +++ PROZESSRECHNER
+++ PROZESSRECHNER +++ PROZESSRECHNER
+++ PROZESSRECHNER +++ PROZESSRECHNER
+++ |
|||||||
|
| 1. Historie der Prozessrechentechnik |
|
|
|
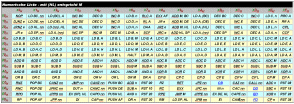
Obwohl die Geschichte der elektronischen Rechentechnik erst bis in die Mitte des letzten Jahrhunderts zurückreicht, hat sie aufgrund eines beispiellosen
Entwicklungstempos eine derartige Fülle von Rechnertypen und entsprechenden Bezeichnungen hervorgebracht, als „jüngstes Kind" die Mikrorechner, dass es geraten
erscheint, an den Anfang eine Übersicht über die bisherige Entwicklung der Digitalrechner und ihrer Anwendungsgebiete zu stellen (Bild
unten).
|
|
| Die mit Elektronenröhren realisierten ersten Digitalrechner (1. Generation, Elektronenrechner) wurden ausschließlich für die Bewältigung umfangreicher
wissenschaftlich-technischer Rechnungen projektiert. Diese Anlagen mit für heutige Maßstäbe riesigen Ausmaßen, großem Energieverbrauch, hohen
Anschaffungs- und Betriebskosten wiesen eine Leistung auf, die gegenwärtig bereits von einem mittleren Taschen- oder Tischrechner erwartet wird. Mit ihnen wurde
jedoch ein neuer Maschinentyp geboren, dessen prinzipielle Struktur und Arbeitsweise nach wie vor das Bild der Rechentechnik prägt. Aufgrund der Anwendung
dieser Anlagen zur Zahlenverarbeitung wurde der Begriff Rechner (Computer) eingeführt, der ebenfalls überdauerte, obwohl sich der Schwerpunkt der
Anwendungen längst auf andere Aufgaben verlagert hat. Diese Veränderung des Einsatzgebietes erfolgte bereits in der 2. Etappe: Die Erfindung und industrielle Fertigung des Transistors ermöglichten den Bau von Rechenanlagen mit geringeren Abmessungen, niedrigeren Herstellungs- und Betriebskosten und damit den breiteren Einsatz der Rechner in Industrie und Wirtschaft (2. Generation). Aus der Synthese mit der mechanischen Lochkartentechnik entstanden Anlagen, die vorwiegend zur kommerziellen Datenverarbeitung eingesetzt wurden. Dementsprechend wurde der Begriff elektronische Datenverarbeitungsanlage (EDVA) zur am häufigsten verwendeten Bezeichnung für Digitalrechner. Im Unterschied zur wissenschaftlich-technischen Rechnung stehen bei der Datenverarbeitung die Eingabe und Ausgabe und die Archivierung (Speicherung) großer Zahlenmengen im Vordergrund, während die Verarbeitungsvorgänge (Rechenoperationen) im Verhältnis dazu in den Hintergrund treten. In die 2. Etappe fielen aber auch die ersten Versuche, Rechner als Steuereinrichtungen für industrielle Prozesse einzusetzen (Prozessrechner). Damit wurde ein Anwendungsfeld mit grundsätzlich anderem Anforderungsprofil erschlossen. Diese Rechner hatten und haben in erster Linie die Aufgabe, Meßgrößen des Prozesses zu „beobachten", um daraus Stellbefehle zu „berechnen", die entweder direkt den Prozess steuern oder (wie für die 2. Etappe typisch war) den Bediener bei der Prozessführung unterstützen. Entscheidend ist, dass immer bestimmte, durch die Prozessdynamik bedingte Zeitforderungen zwischen Aufnahme und Ausgabe der Information eingehalten werden müssen. Es entsteht also die neue Situation, dass die „Rechenergebnisse" nur dann brauchbar sind, wenn sie nicht nur richtig, sondern auch in einer vorgegebenen Zeit zur Verfügung stehen. Für diese Klasse von Anwendungen wurde der Begriff Echtzeitverarbeitung (real time processing) eingeführt. Technisch gesehen, müssen diese Rechner mit spezifischen Details ausgerüstet werden, um insbesondere ihre Aufnahmebereitschaft zu beschleunigen (Unterbrechungssystem) und ihre Zuverlässigkeit zu erhöhen. Im Gegensatz zur EDV-Anlage, die nacheinander die unterschiedlichsten Aufgaben für mehrere Nutzer lösen muss und damit ständig mit anderen Programmen geladen wird, laufen die Steuerrechner ständig mit einem Programm. Die Aufspaltung in die Linie der EDV-Anlagen und der Prozessrechner ist auch in den folgenden Entwicklungsetappen zu erkennen, obgleich die technischen Unterschiede beider Rechnertypen wieder weitgehend verschwinden. Die 3. Etappe wurde von den Rechnern der 3. Generation (ESER-Anlagen) geprägt. Sie sind eine direkte Weiterentwicklung der EDV-Anlagen der 2. Generation. Die Verfügbarkeit integrierter Schaltkreise, verbunden mit verbesserten Rechnerstrukturen, führte zu einer weiteren Steigerung des Leistungs-Kosten-Verhältnisses dieser großen Rechenanlagen. Charakteristisch für diese Anlagen ist ein modularer Aufbau, bestehend aus Zentraleinheiten (Digitalrechnern) mit aufsteigender Leistungsfähigkeit (Rechnerfamilien) und aus einer Palette verschiedener Eingabe/Ausgabe-Geräte und Massenspeicher (Magnetplatten-, Magnetbandgeräte). Damit bot sich erstmals die Möglichkeit, an das Anwendungsprofil angepasste Konfigurationen zusammenzustellen. Obwohl diese Anlagen vorwiegend für die Zwecke der kommerziellen Datenverarbeitung eingesetzt wurden und werden, sind sie aufgrund ihrer technischen Merkmale ebenso für wissenschaftlich-technische Berechnungen als auch für Prozesssteuerungen einsetzbar (Universalrechner). In jedem Fall handelt es sich aber um Rechenanlagen, die aufgrund ihrer Abmessungen und Klimaforderungen eigene Räume zur Aufstellung erfordern (Rechenzentrum). Die Linie der Prozessrechner mündete in dieser 3. Etappe zu einem Teil wieder in die Linie der EDV-Anlagen, entwickelte sich aber auch eigenständig weiter, um insbesondere volumenmäßig (zwangsläufig auch leistungsmäßig) kleinere Anlagen bereitzustellen. Damit entstanden neue Begriffe, wie Kleinrechner, Kleinsteuerrechner, Kompaktrechner, Minirechner. |
|
| Die Kleinrechner eröffneten zugleich ein weiteres Einsatzgebiet der elektronischen Rechentechnik, nämlich die dezentrale Datenverarbeitung und die Verfügbarkeit von Rechnerleistung in der Nähe des Arbeitsplatzes. Die Nachteile des Rechenzentrumbetriebs, insbesondere der begrenzte Zugriff des Nutzers und die
langen Programmumschlagzeiten, konnten damit bei einigen Anwendungen wieder vermieden werden. Um das Bild zu vervollständigen, muss auch vermerkt
werden, dass in der 3. Etappe die Außenseiterlinie der Superrechner begann. Zielstellung beim Entwurf dieser Maschinen war und ist, ohne Rücksicht auf ökonomische Grenzen die für den jeweiligen Stand der Elektronik maximale Rechenleistung zu erreichen. Das Leistungsvermögen solcher Anlagen reicht inzwischen bis zu einigen 100 Millionen Rechenoperationen je Sekunde. Sie sind damit die eigentlichen Nachfolger der Digitalrechner der 1. Generation in dem Sinne, dass sie für die Ausführung wissenschaftlich-technischer Berechnungen extremen Umfangs bestimmt sind (z. B. in der wissenschaftlichen Forschung, für die Simulation komplizierter Systeme). Um die Notwendigkeit und die Leistungsfähigkeit solcher Rechner zu demonstrieren, wollen wir folgendes Zahlenbeispiel betrachten: Für die Vorausberechnung der globalen Wetterentwicklung mit Hilfe eines mathematischen Modells, das die physikalischen Vorgänge in der Atmosphäre näherungsweise nachbildet, seien nach Eingabe des Ist-Zustandes für eine 24-h-Prognose 1010...1011 Rechenoperationen notwendig. Ein mittlerer Rechner der 3. Generation mit einer typischen Operationsgeschwindigkeit von etwa 300000 Operationen je Sekunde würde dazu eine Rechenzeit zwischen 10 und 100 Stunden benötigen, also letztlich der realen Wetterentwicklung hinterherlaufen. Ein Superrechner mit 100 Millionen Operationen je Sekunde leistet die gleiche Arbeit in 2...20 Minuten. In den 70er Jahren wurde nun eine 4. Etappe der elektronischen Rechentechnik eingeleitet, die durch die Mikrorechner geprägt ist. Eigentlich sind die Mikrorechner „nur" ein folgerichtiges Ergebnis der Weiterentwicklung der integrierten Schaltungstechnik, in dem es technisch möglich wird, zunehmend größere Funktionseinheiten auf einem Schaltkreis zu integrieren und damit größere Baugruppen bzw. komplette Rechner mit dieser Technologie herzustellen. In funktioneller Hinsicht unterscheiden sie sich nicht von den anderen Rechnertypen. Leistungsmäßig bildeten sie (zumindest anfangs) die unterste Schicht der Rechner. Trotzdem haben sie einen Umwälzungsprozess ausgelöst, der durchaus berechtigt, von einer neuen Etappe der elektronischen Rechentechnik zu sprechen. Wodurch ist dies begründet? Die neue Qualität dieser Rechner besteht darin, dass leistungsfähige Digitalrechner in Form von Baugruppen bzw. Bauelementen zur Verfügung stehen und nicht mehr wie bisher als eigenständige Geräte produziert werden. |
|
Dies hat vor allem 2 Auswirkungen.
Zu 1. Da das Kosten-Leistungs-Verhältnis in der bisherigen Entwicklung zugunsten der großen Rechenanlagen sprach, herrschte als Grundtendenz die
zunehmende Zentralisierung der Rechnerleistung vor. Dementsprechend musste sowohl in der Datenverarbeitung als auch bei wissenschaftlich-technischen Rechnungen
der Transport der Eingabe- und Ausgabeinformationen entweder körperlich in Form von geeigneten Datenträgern oder elektrisch mit Hilfe von Datenübertragungseinrichtungen zu bzw. von den Rechenzentren bewerkstelligt werden. In der Prozesssteuerung war man bemüht, möglichst viele Aufgaben durch einen
zentralisierten Rechner parallel abarbeiten zu lassen, was zu einer weiträumigen Verkabelung zwischen Rechner und Peripherie führte.
|
|
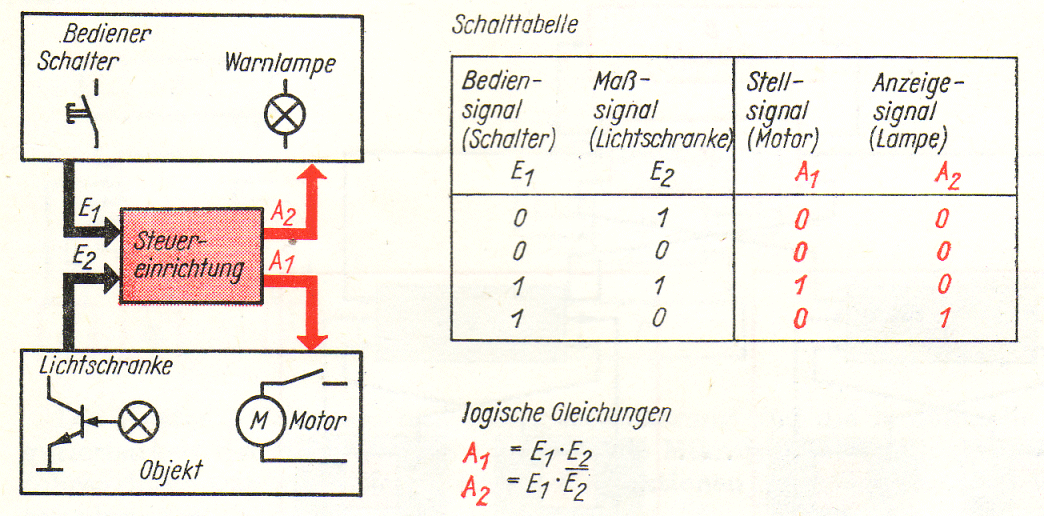
Bisher haben wir vorausgesetzt, dass die Steuereinrichtung durch einen Rechner realisiert wird, wie es auch dem Anliegen dieses Buches entspricht. Trotzdem sollen im folgenden alternative Lösungen betrachtet werden, um zu erkennen,
unter welchen Bedingungen ein Einsatz von Rechnern zweckmäßig und möglich ist.
|
| 2. Grundlegender Rechneraufbau |
|
|
|
|
|
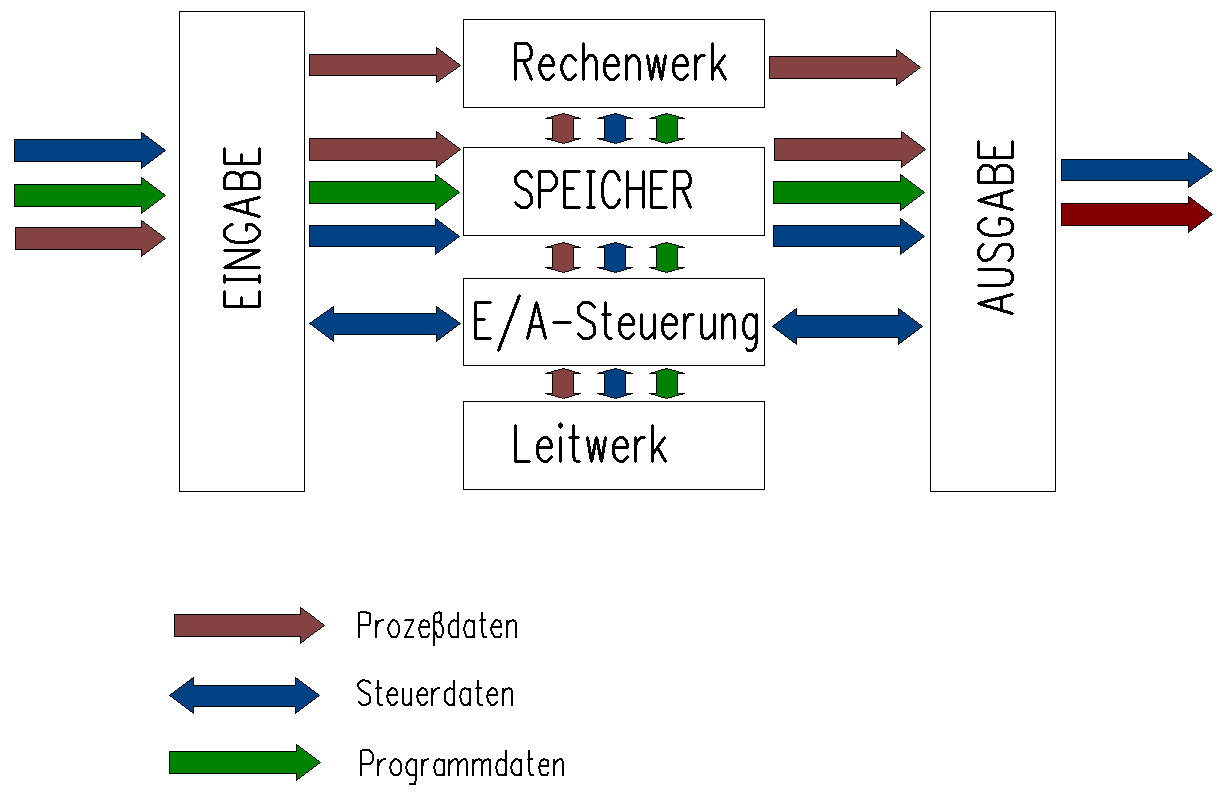
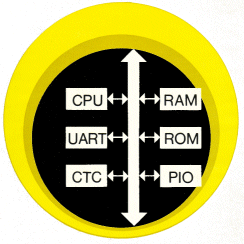
Die Bezeichnung Rechner (Computer) ist dem ursprünglichen Anwendungsgebiet dieser Anlagen entlehnt, nämlich der Ausführung wissenschaftlich-technischer Berechnungen. Für das Verstehen des Aufbaus und der Arbeitsweise ist es dagegen zweckmäßig, zunächst keine Assoziationen zu solchen Anwendungen herzustellen oder gar mit dem Rechnerbegriff die Vorstellung von elektronischen Tisch- und Taschenrechnern zu verbinden. Als Rechner wollen wir vielmehr programmgesteuerte elektronische Einrichtungen bezeichnen, die Informationen verarbeiten, speichern, an die Umwelt ausgeben und von dieser aufnehmen können. Dementsprechend besteht ein Rechner aus folgenden Funktionseinheiten (oben): |
Grundlegender Rechneraufbau und Datentransfer
|
|
Genauer müssen wir dabei noch klären, was in diesem Fall unter Information zu verstehen ist. |
| 3. Informationsdarstellung in Rechnern |
|
|
|
|
|
Informationen können rechnerintern nur durch Binärwörter endlicher Breite (Datenwort, Daten) dargestellt und verarbeitet werden. Vereinfachend nehmen wir zunächst an, dass die Wortbreite für einen bestimmten Rechnertyp konstant
ist, also die Information immer in folgender Form transportiert, verarbeitet und gespeichert wird: Jede Wortstelle besteht aus einem Binärzeichen (Bit), das die Werte 0 oder 1 annehmen kann. (Diese Informationsdarstellung ist durch die Tatsache bedingt, dass Rechner bisher ausschließlich mit Hilfe solcher elektronischer Grundbausteine realisiert werden, die zwei verschiedene elektrische Zustände einnehmen können.) |
| Bei einer Wortbreite von N bit lassen sich insgesamt 2n verschiedene Binärwörter bilden, also 2n verschiedene Zustände darstellen. Betrachten wir als Beispiel den Fall N = 3. Die 8 verschiedenen Binärwörter lauten: 000, 001, 010, 100, 011, 110, 101, 111. Diesen Wörtern kann nun eine beliebige Bedeutung zugeordnet werden. So könnten diese 8 Wörter zum Beispiel benutzt werden, um 8 Zahlenwerte (0, 1, 7 oder -4, -3, ..., 0, -.., -}-3), 8 Buchstaben (A, B, C, .-., H), 8 verschiedene Farben eines Gegenstandes oder 8 Steueranweisungen für ein Gerät (Motor ein, Heizung ein, . . .) usw. zu verschlüsseln. Die Festlegung der jeweils gültigen Zuordnung (Verschlüsselung) wird als Kode bezeichnet. Damit können wir den Rechnerbegriff wie folgt konkreter fassen: Ein Rechner ist eine programmgesteuerte elektronische Einrichtung zur Verarbeitung, Speicherung und Eingabe/Ausgabe von Binärwörtern endlicher (meist konstanter) Breite, denen eine beliebige Bedeutung zugeordnet werden kann. (Die Zuordnung von Zahlenwerten ist dabei ein Spezialfall.) |
|
| Die Wortbreite ist somit eine wichtige Kenngröße eines Rechners. Sie ist bei den einzelnen Rechnertypen verschieden. Die Rechenanlagen der 3. Generation
(ESER-Reihe) weisen z. B. eine Standard-Wortbreite von 32 bit,
Prozess- und
Minirechner meist 16 bit auf. Die Mikrorechner werden inzwischen mit Wortbreiten von 4, 8, 16 und 32 bit produziert, wobei der Schwerpunkt der Fertigung bei 8- und 16-bit-Prozessoren liegt. Wir wollen uns deshalb der Frage zuwenden, wie muss oder sollte die Wortbreite eines Rechners gewählt werden. Die folgende Tabelle zeigt anhand einiger Zahlenpaare, wie durch Verdoppelung der Wortbreite die Anzahl der kodierbaren Zustände exponentiell wächst: Wortbreite N Anzahl der Binärwörter 2n 4 16 8 256 16 65 536 32 4294367296 |
|
| Es ist zunächst naheliegend anzunehmen, dass die Wortbreite entsprechend der Anzahl der Zustände gewählt wird, die im jeweiligen Anwendungsfall unterschieden werden müssen. Betrachten wir einige Beispiele: |
|
|
1. Um die Dezimalziffern 0...9 zu kodieren, reicht bereits eine Wortbreite von 4
bit. Die Kodetabelle könnte wie folgt lauten: Diese Zuordnung wird oft angewendet und als BCD-Kode bezeichnet. |
|
| 2. Die Kodierung eines kompletten Zeichensatzes für Textausgabe (Groß- und Kleinbuchstaben, Ziffern, Sonderzeichen) erfordert bereits eine Wortbreite von 7 bit. Hierfür ist eine Kodetabelle (ISO-7-bit-Kode) international standardisiert worden. | |
| 3. Sollen rationale Zahlen rechnerintern kodiert werden, dann sind mit wachsendem Zahlenbereich sehr schnell große Wortbreiten notwendig. Die Darstellung aller sechsstelligen positiven und negativen Zahlen im Festkommaformat (Komma beliebig, aber fest vereinbart) erfordert z. B. die Unterscheidung von 1999999 Zahlen (Zuständen) und damit eine Wortbreite von 21 bit. | |
| Aus den Beispielen ist ersichtlich, dass bei Anwendung der Rechner zur Zahlenverarbeitung im Interesse eines großen darstellbaren Zahlenbereichs (und damit einer hohen Rechengenauigkeit) eine möglichst große Wortbreite zu realisieren ist. Dem steht entgegen, dass die Wortbreite entscheidend den technischen Aufwand und damit die Kosten eines Rechners bestimmt. Elektronische Speicherzellen können nur ein Bit speichern, die Logikbausteine verarbeiten nur einstellige Binärwörter, so dass alle diese Baustufen N-fach parallel angeordnet werden müssen. Als Transportwege zwischen den Baugruppen werden Bündel ven jeweils N Leiterbahnen erforderlich. Es ist folglich beim Entwurf eines Rechners bzw. seines Zentralprozessors notwendig, einen Kompromiss zwischen Wortbreite und Leistungsfähigkeit zur Zahlenverarbeitung zu schließen. Dies führt oft dazu, dass die durch die Wortbreite gegebene Anzahl unterschiedlicher Wörter nicht ausreicht, um die für den jeweiligen Anwendungsfall benötigten Zustände zu kodieren. Insbesondere gilt das bei Zahlenrechnungen. Der Ausweg kann nur darin bestehen, dass mehrere Binärwörter zur Informationsdarstellung herangezogen werden. Da aber Rechner meist nur Binärwörter in ihrer Standardwortbreite in einem Schritt verarbeiten, transportieren und speichern können, müssen dann diese Vorgänge in zeitlich aufeinanderfolgenden Schritten ausgeführt werden. Das heißt, anstelle eines Befehls sind bereits Programme notwendig, um Elementaroperationen zu realisieren. Folglich werden sich die Ausführungszeiten erheblich vergrößern. Es gilt also zu vermerken: |
|
| Trotz einer endlichen Wortbreite lassen sich rechnerintern beliebig viele Zustände (bzw. ein beliebig großer Zahlenbereich) darstellen und verarbeiten. Überschreitet die Anzahl der Zustände aber den durch die Wortbreite des Rechners vorgegebenen Bereich, dann geht dies zu Lastender Arbeitsgeschwindigkeit des Rechners. Durch eine „geschickte" Kodierung der Zahlen kann die Arbeitsgeschwindigkeit in bestimmtem Maße beeinflusst werden. In der rechentechnischen Literatur wird daher dieser Problematik gewöhnlich breiter Raum gewidmet. Beim Rechnereinsatz für Steuerungsaufgaben spielen dagegen Rechenprozesse meist eine untergeordnete Rolle. Es soll deshalb nur die einfachste Möglichkeit der Kodierung von Dezimalzahlen und zwar die Kodierung als Dualzahl ohne Vorzeichen, betrachtet werden In diesem Fall wird jeder Bitstelle des Datenwortes wie folgt eine Wertigkeit mit aufsteigenden Potenzen zur Basis 2 zugeordnet: |
|
| Folglich lassen sich mit dieser ,Kodierung die natürlichen Zahlen im Bereich von 0 ... 2r' - 1 darstellen. Betrachten wir einige Kodierbeispiele für die bei Mikrorechnern oft verwendete Wortbreite von 8 bit: Der darstellbare Zahlenbereich reicht dementsprechend von 0 ... 255, und es gelten die folgenden Zuordnungen: 1 0 I 1 1 0 0 1 f 271 128 +32 +16 +2 +1 = 179 0 I 1 I 0 0 1 T 1 0 0 64 +8 +4 = 76 1 1 1 1 1 I 1 1 ( 1 128 +64 +32 +16 +8 +4 +2 +1 = 255. |
| 4. Befehlsabarbeitungszyklus |
|
|
|
|
|
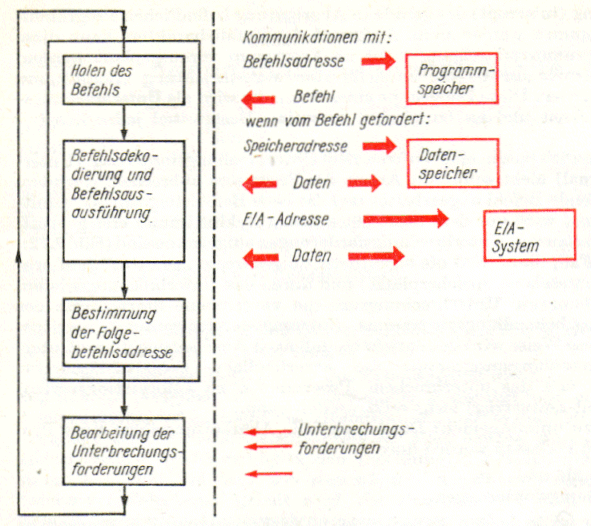
Von den im Bild 2.11 dargestellten Funktionseinheiten ist der Zentralprozessor der eigentliche Kern, der aktive Teil des Rechners.
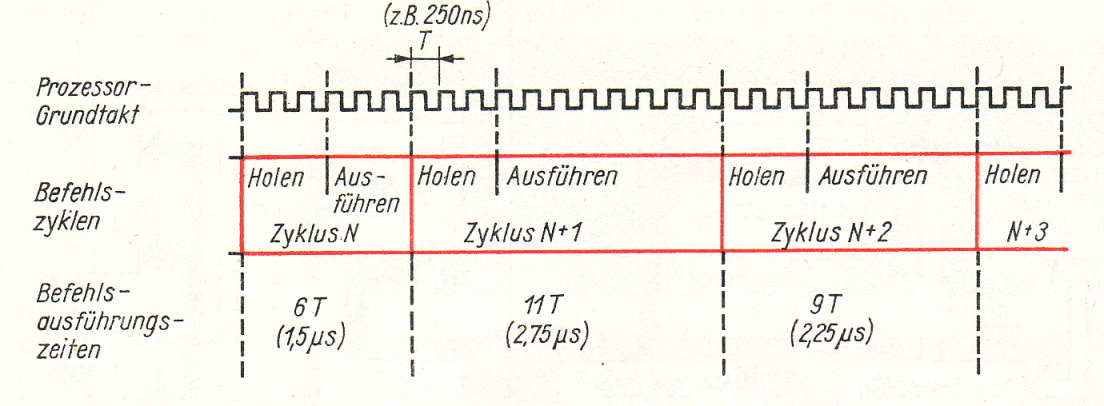
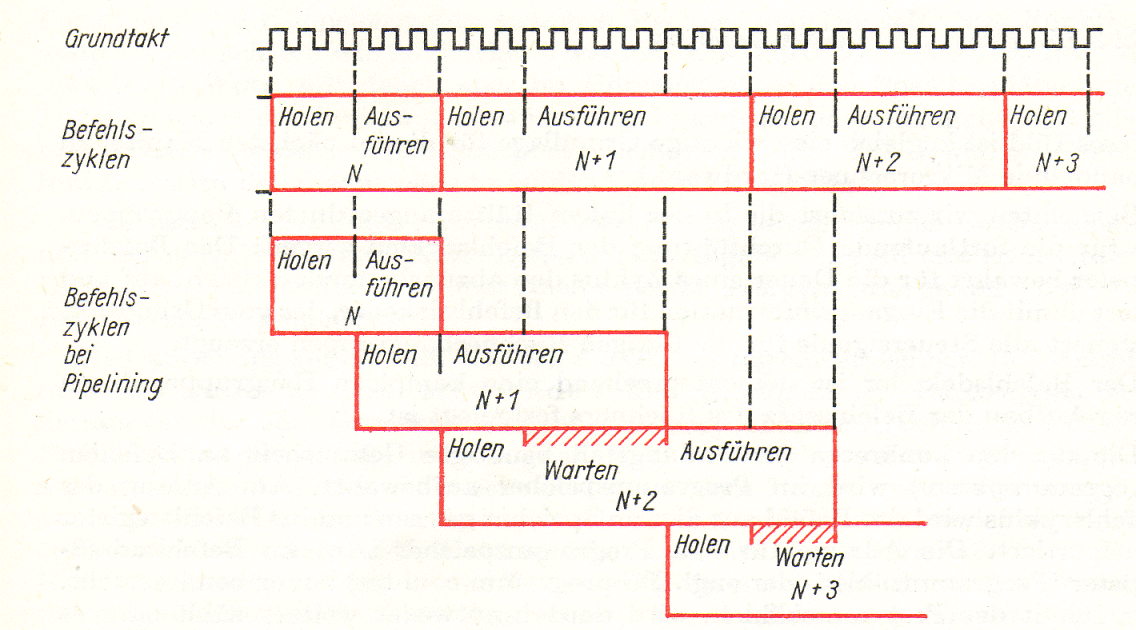
Als Zentralprozessor (ZVE zentrale Verarbeitungseinheit oder engl. CPU central processing unit) wird die Funktionseinheit eines Rechners bezeichnet, die, von einem Grundtakt gesteuert, dafür sorgt, dass in endloser Folge Befehle ausgeführt werden. Jeder Prozessor besitzt dabei einen bestimmten Befehlssatz, d. h. eine Menge von Befehlswörtern, die er „versteht" und ausführen kann. Mit Anlegen des Grundtaktes beginnt der Prozessor seine Arbeit und durchläuft fortlaufend sog. Befehlszyklen. |
Unter einem Befehlszyklus (Befehlsschleife) wird der Zeitabschnitt zur Ausführung eines Befehls verstanden. Während dieser Zeit muss der Prozessor die folgenden Aufgaben erfüllen:
Befehlszyklus und Kommunikationsarten in den Phasen des Befehlszyklus
|
|
|
Sprungbefehle und Unterbrechungsforderungen Die Wirkung ist in beiden Fällen gleich: Die Fortsetzung des Programms erfolgt nicht mit dem Folgebefehl des Programmspeichers, sondern an einer vom Programmierer festgelegten anderen Stelle.
Das Wesen ist dabei aber grundverschieden: Durch einen Sprung wird eine determinierte Verzweigung im Programm geschaffen, um auf bestimmte Ereignisse, die bei der Programmausführung eingetreten sind, zu reagieren.
Prozessortakt und Befehlszyklus
|
| 5. Rechnerbaugruppen |
|
|
|
|
|
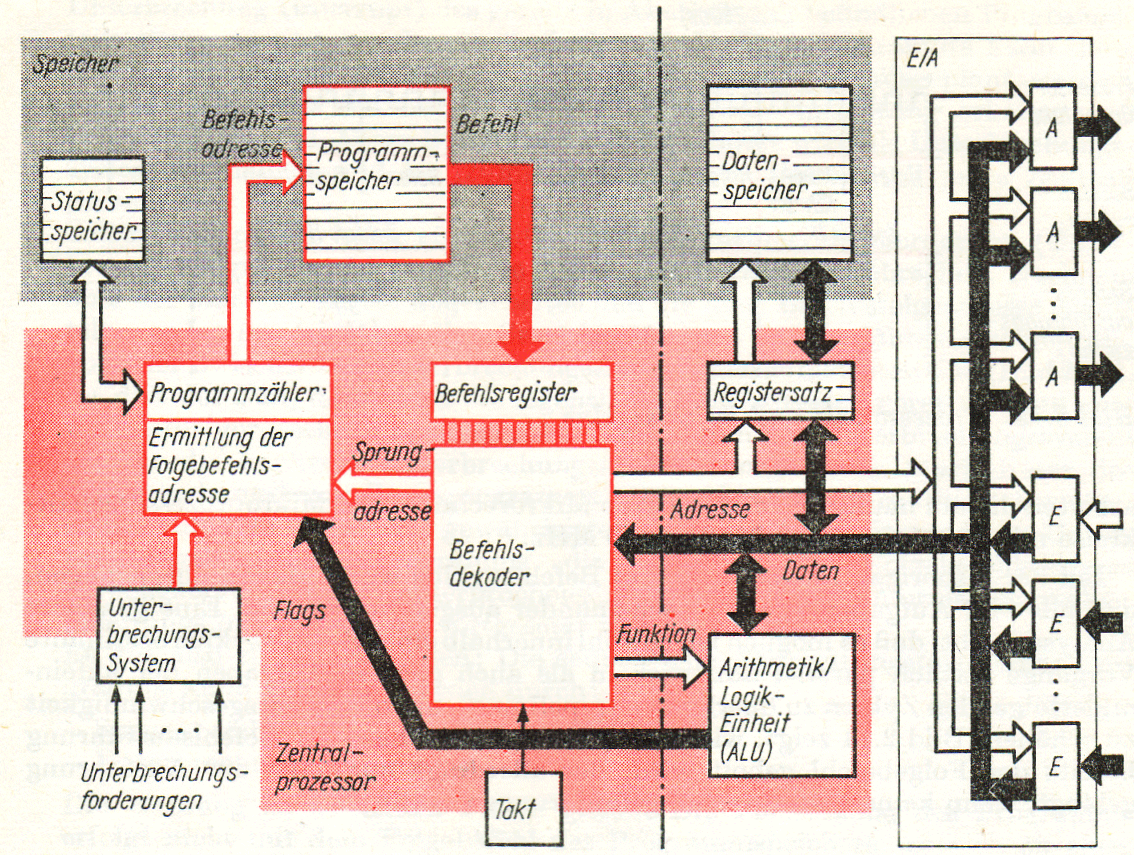
Aus der Aktionsfolge des Befehlszyklus (Bilder zu 4) lassen sich unmittelbar die notwendigen Baugruppen eines Prozessors und eines Rechners ableiten. Bild
oben zeigt die Blockstruktur, die wir im folgenden schrittweise entwickeln wollen. Betrachten wir zunächst die in der linken Hälfte angeordneten Baugruppen, die für die fortlaufende Durchführung der Befehlszyklen sorgen: Das Befehlsregister bewahrt für die Dauer eines Zyklus den abzuarbeitenden Befehl auf und liefert damit die Eingangsinformation für den Befehlsdekoder, der vom Grundtakt gesteuert alle Steuersignale für die übrigen Rechnerbaugruppen erzeugt. Der Befehlsdekoder ist dementsprechend eine komplexe Baugruppe, durch deren Aufbau der Befehlssatz des Rechners festgelegt ist. |
|
Die für den konkreten Anwendungsfall benötigte Gesamtheit an Befehlen (Programmsystem) wird im Programmspeicher aufbewahrt. Am Anfang des Befehlszyklus wird der Befehl aus diesem Speicher gelesen und ins Befehlsregister
transportiert. Die Adresse für den Programmspeicher wird im
Befehlsadressregister (Programmzähler oder engl. PC programm counter) zuvor bereitgestellt. |
| 6. Verwandte Themen |
|
|
|
|
|
Was ist alles mit dem Betriebssystem eines Microcomputers verwandt? Antwort: faktisch der gesamte Bereich der Digitalelektronik und sowieso die gesamte Technik der Software-Technologie der Vergangenheit, Gegenwart sowie zumindest der nächsten Zukunft. | ||||||||||||||||||
|
|
|
||||||||||||||||||
|
|
|
|
zur Hauptseite |
© Samuel-von-Pufendorf-Gymnasium Flöha | © Frank Rost Februar 2001 |
|
... dieser Text wurde nach den Regeln irgendeiner Rechtschreibreform verfasst - ich hab' irgendwann einmal beschlossen, an diesem Zirkus nicht mehr teilzunehmen ;-) „Dieses Land braucht eine Steuerreform, dieses Land braucht eine Rentenreform - wir schreiben Schiffahrt mit drei „f“!“ Diddi Hallervorden, dt. Komiker und Kabarettist |
|
Diese Seite wurde ohne Zusatz irgendwelcher Konversationsstoffe erstellt ;-) |