| Der ASCII-Code - The American Standard Code of Information Interchange |
|
|
Letztmalig dran rumgefummelt: 21.06.26 04:24:12 |
| Der ASCII-Code wurde zuerst
am 17. Juni 1963 von der American Standards Association (ASA) als Standard
ASA X3.4-1963 gebilligt - Vorlage:Rp - Vorlage:Rp und 1967/1968 wesentlich
sowie zuletzt im Jahr 1986 (ANSI X3.4-1986) von ihren Nachfolgeinstitutionen
aktualisiert und wird noch benutzt. Die Zeichenkodierung definiert 128
Zeichen, bestehend aus 33 nicht druckbaren sowie den folgenden 95 druckbaren
Zeichen, beginnend mit dem Leerzeichen. Die Geschichte des ASCII-Codes ist deshalb so fundamental, weil durch diesen die Gr÷▀e unserer sinnvoll kleinen Informationspakete auf 8 geschraubt wurde und in absehbarer Zeit diese auch weiterhin verwendet werden bzw. bei Bedarf durch mehrmaliges Einlesen sowie Aneinanderreihen Vielfache des Bytes zum Tragen kommen. Urspr³nglich war der ASCII-Code allerdings ein 7-Bit-Code, was man an diversen Stellen (E-Mail-Systeme) auch heute noch bemerken kann. 01001101 01010101 01010100 01010100 01001001 01001001 01000011 01001000 01001000 01000001 01000010 01000101 01000100 01000101 01001110 01010011 01000101 01001110 01000110 01010110 01000101 01010010 01000111 01000101 01010011 01010011 01000101 01001110 ... das hei▀t: Mutti, ich habe den Senf vergessen!!! |
|||||||
|
1. Zur Geschichte 2. Der ASCII-Code 3. ASCII-Code in der heute praktischen Anwendung 4. Marias Hinrichtung 5. Links & verwandte Themen |
|||||||
|
|||||||
|
| 1. Zur Geschichte |
|
|
|
|
|
Zum ASCII-Code hat die Nachrichtentechnik ³ber
einige kleine Umwege gefunden, denn anfõnglich ging das Bestreben danach,
die Anzahl der Bitkombinationen klein zu halten. Claude Baudot verwendete 5
Bits mit entsprechenden Konsequenzen - es musste Umgeschalten werden
zwischen Buchstaben und Ziffern. Auf 32 Kombinationen sind eben nicht 26
Zeichen und 10 Ziffern zu codieren.
␣!"#$%&'()*+,-./0123456789:;<=>? Die Zeichen umfassen das lateinische Alphabet in Gro▀- und Kleinschreibung, die zehn arabischen Ziffern sowie einige Satz- und Steuerzeichen. Der Zeichenvorrat entspricht weitgehend dem einer Tastatur oder Schreibmaschine f³r die englische Sprache. In Computern und anderen elektronischen Gerõten, die Text darstellen, wird dieser in der Regel gemõ▀ ASCII oder abwõrtskompatibel (z. B. ISO 8859, UTF-8) dazu gespeichert. |
||||||||
|
|
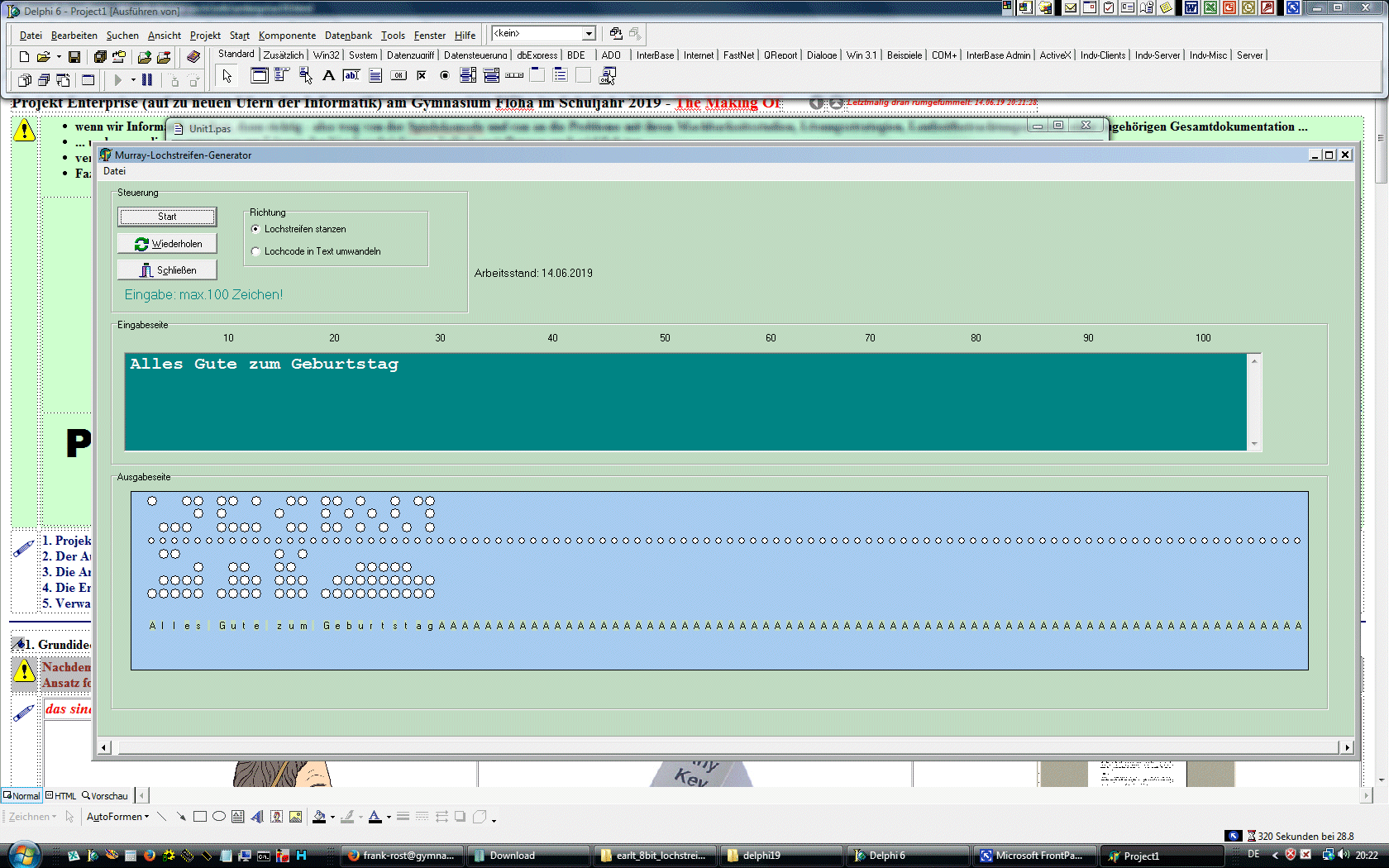
Der ASCII Code blickt auf eine lange Geschichte zur³ck. Seine Anfõnge liegen in der Telegrafie und dem Morse-Code sowie dem 5-Bit-Murray-Code, den der neuseelõndische Erfinder Donald Murray zwischen 1901 und 1932 entwickelte. Die erste Version des ASCII Codes wurde 1963 von der ASA, der American Standards Association, herausgebracht. Die ASA war ein Vorlõufer des American National Standards Institute (ANSI), dem US-amerikanischen Gegenst³ck zum Deutschen Institut f³r Normung (DIN). 1968 erschien die bis heute g³ltige Fassung des Zeichensatzes. | ||||||||
|
|
|
||||||||
Spezielle Zeichen und Zahlencodes
|
|||||||||
|
Eine Form der Zeichenkodierung war der Morsecode. Er wurde
mit der Einf³hrung von Fernschreibern aus den Telegrafennetzen verdrõngt und
durch den Baudot-Code und Murray-Code ersetzt. Vom F³nf-Bit-Murray-Code zum
Sieben-Bit-ASCII war es dann nur noch ein kleiner Schritt ¢ auch ASCII wurde
zuerst f³r bestimmte amerikanische Fernschreiber-Modelle, wie den Teletype
ASR33, eingesetzt. In den Anfõngen des Computerzeitalters entwickelte sich
ASCII zum Standard-Code f³r Schriftzeichen. Als Beispiel wurden viele
Bildschirme (z. B. VT100) und Drucker nur mit ASCII angesteuert. |
|||||||||
|
|
| 2. Der ASCII-Code |
|
|
|
|
|
Der ASCII-Code generiert die Zeichen des englischsprachigen Alphabets in Gro▀- und Kleinschreibweise sowie die zehn Ziffern und einige Sonderzeichen inclusive 32 Steuerzeichen f³r Fernschreiber, denn dies war das Basis-Anliegen. | ||||||||
|
|||||||||
| 3. ASCII-Code in der heute praktischen Anwendung |
|
|
|
|
|
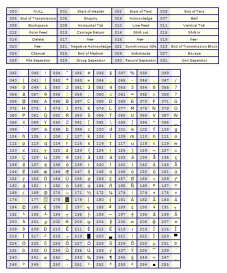
Die ersten 32
ASCII-Zeichencodes (von 00 bis 1F) sind f³r Steuerzeichen (control character)
reserviert; siehe dort f³r die Erklõrung der Abk³rzungen in obiger Tabelle.
Das sind Zeichen, die keine Schriftzeichen darstellen, sondern die zur
Steuerung von solchen Gerõten dienen (oder dienten), die den ASCII verwenden
(etwa Drucker). Steuerzeichen sind beispielsweise der Wagenr³cklauf f³r den
Zeilenumbruch oder Bell (die Glocke); ihre Definition ist historisch
begr³ndet. Code 20 (SP) ist das Leerzeichen (engl. space oder blank), das in einem Text als Leer- und Trennzeichen zwischen W÷rtern verwendet und auf der Tastatur durch die Leertaste erzeugt wird. Die Codes 21 bis 7E sind alle druckbaren Zeichen, die sowohl Buchstaben, Ziffern und Satzzeichen (siehe Tabelle) enthalten. Code 7FH (alle sieben Bits auf eins gesetzt) ist ein Sonderzeichen, das auch als äL÷schzeichenō bezeichnet wird (DEL). Dieser Code wurde fr³her wie ein Steuerzeichen verwendet, um auf Lochstreifen oder Lochkarten ein bereits gelochtes Zeichen nachtrõglich durch das Setzen aller Bits, d. h. durch Auslochen aller sieben Markierungen, l÷schen zu k÷nnen ¢ einmal vorhandene L÷cher kann man schlie▀lich nicht mehr r³ckgõngig machen. Bereiche ohne L÷cher (also mit dem Code 00) fanden sich am Anfang und Ende eines Lochstreifens (NUL). Aus diesem Grund geh÷rten zum eigentlichen ASCII-Code nur 126 Zeichen, denn den Bitmustern 0 (0000000) und 127 (1111111) entsprachen keine Zeichencodes. Der Kodierung 0 wurde spõter in der Programmiersprache C die Bedeutung äEnde der Zeichenketteō beigelegt; dem Zeichen 127 wurden verschiedene grafische Symbole zugeordnet. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
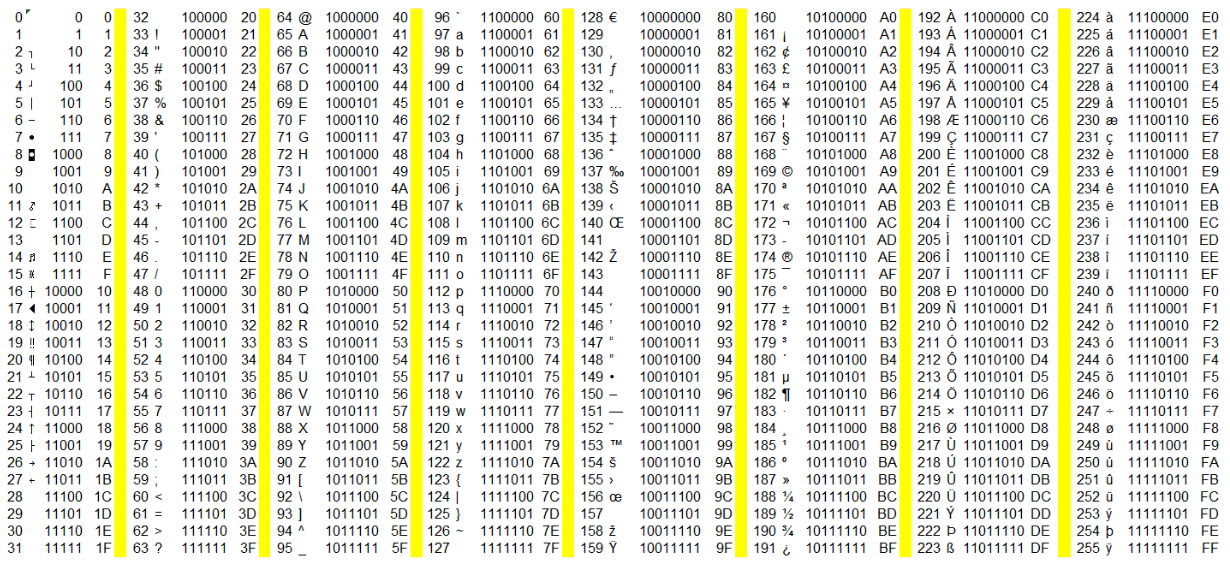
ASCII-Tabelle [Bearbeiten]Die ASCII-Tabelle enthõlt alle Kodierungen des ASCII-Zeichensatzes; siehe Steuerzeichen f³r die Bedeutung der Abk³rzungen in der rechten Spalte:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
... wirklich Wichtiges zum ASCII-Code, wenn man damit technisch richtig
arbeiten muss - ansonsten gen³gt das oben stehende
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| 4. Erweiterungen des ASCII-Zeichensatzes |
|
|
|
|
|
ASCII enthõlt keine
diakritischen Zeichen, die in fast allen Sprachen auf der Basis des
lateinischen Alphabets verwendet werden. Der internationale Standard
ISO 646
(1972) war der erste Versuch, dieses Problem anzugehen, was allerdings zu
Kompatibilitõtsproblemen f³hrte. Er ist immer noch ein Sieben-Bit-Code, und
weil keine anderen Codes verf³gbar waren, wurden einige Codes in neuen
Varianten verwendet. So ist etwa die ASCII-Position 93 f³r die rechte eckige Klammer (]) in der deutschen Zeichensatz-Variante ISO 646-DE durch das gro▀e U mit Trema (Umlaut) (▄) und in der dõnischen Variante ISO 646-DK durch das gro▀e A mit Ring (Krou×ek) (┼) ersetzt. Bei der Programmierung mussten dann die in vielen Programmiersprachen benutzten eckigen Klammern durch die entsprechenden nationalen Sonderzeichen ersetzt werden. Das verringerte die Lesbarkeit des Programmcodes und f³hrte oft zu ungewollt komischen Ergebnissen, indem etwa die Einschaltmeldung des Apple II von äAPPLE ][ō zu äAPPLE ▄─ō mutierte. Verschiedene Hersteller entwickelten eigene Acht-Bit-Codes. Der Codepage 437 genannte Code war lange Zeit der am weitesten verbreitete, er kam auf dem IBM-PC unter MS-DOS, und kommt heute noch in DOS- oder Eingabeaufforderungsfenstern von Microsoft Windows, zur Anwendung. Auch bei spõteren Standards wie ISO 8859 wurden acht Bits verwendet. Dabei existieren mehrere Varianten, zum Beispiel ISO 8859-1 f³r die westeuropõischen Sprachen. Deutschsprachige Versionen von Windows (au▀er DOS-Fenster) verwenden die auf ISO 8859-1 aufbauende Kodierung Windows-1252 ¢ daher sehen z. B. bei unter DOS erstellten Textdateien die deutschen Umlaute falsch aus, wenn man sie unter Windows ansieht. Viele õltere Programme, die das achte Bit f³r eigene Zwecke verwendeten, konnten damit nicht umgehen. Sie wurden im Laufe der Zeit oft den neuen Erfordernissen angepasst. Um den verschiedenen Anforderungen der verschiedenen Sprachen gerecht zu werden, wurde der Unicode (in seinem Zeichenvorrat identisch mit ISO 10646) entwickelt. Er verwendet bis zu 32 Bit pro Zeichen und k÷nnte somit ³ber vier Milliarden verschiedene Zeichen unterscheiden, wird jedoch auf etwa 1 Million erlaubte Code-Werte eingeschrõnkt. Damit k÷nnen alle bislang von Menschen verwendeten Schriftzeichen dargestellt werden, sofern sie in den Unicode-Standard aufgenommen wurden. UTF-8 ist eine 8-Bit-Kodierung von Unicode, die zu ASCII abwõrtskompatibel ist. Ein Zeichen kann dabei ein bis vier 8-Bit-W÷rter einnehmen. Sieben-Bit-Varianten m³ssen nicht mehr verwendet werden, dennoch kann Unicode auch mit Hilfe von UTF-7 in sieben Bit kodiert werden. UTF-8 entwickelt sich zur Zeit (2005) zum einheitlichen Standard unter den meisten Betriebssystemen. So nutzen unter anderem Apples Mac OS X sowie einige Linux-Distributionen standardmõ▀ig UTF-8 und immer mehr Webseiten werden in UTF-8 erstellt. ASCII enthõlt nur wenige Zeichen, die allgemein verbindlich zur Formatierung oder Strukturierung von Text verwendet werden; diese gingen aus den Steuerbefehlen der Fernschreiber hervor. Hierzu zõhlen insbesondere der Zeilenvorschub (Linefeed), der Wagenr³cklauf (Carriage Return), der horizontale Tabulator, der Seitenvorschub (Form Feed) und der vertikale Tabulator. In typischen ASCII-Textdateien findet sich neben den druckbaren Zeichen meist nur noch der Wagenr³cklauf oder der Zeilenvorschub, um das Zeilenende zu markieren, wobei in DOS- und Windows-Systemen ³blicherweise beide nacheinander verwendet werden, bei õlteren Apple- und Commodore-Rechnern (ohne Amiga) nur der Wagenr³cklauf, auf Unix-artigen Systemen sowie Amiga-Systemen nur der Zeilenvorschub. Die Verwendung weiterer Zeichen zur Textformatierung ist bei verschiedenen Anwendungsprogrammen zur Textverarbeitung unterschiedlich. Zur Formatierung von Text werden inzwischen eher Markup-Sprachen wie z. B. HTML verwendet. |
Kompatible ZeichenkodierungenViele Zeichenkodierungen sind so entworfen, dass sie f³r Zeichen im Bereich 0ģ127 den gleichen Code verwenden wie ASCII und den Bereich ³ber 127 f³r weitere Zeichen benutzen. Kodierungen mit fester Lõnge (Auswahl)Hier steht eine feste Anzahl Bytes f³r jeweils ein Zeichen. In den meisten Kodierungen ist das ein Byte pro Zeichen, bei den ostasiatischen Schriften zwei oder mehr Byte pro Zeichen.
Kodierungen mit variabler LõngeUm mehr Zeichen kodieren zu k÷nnen, werden die Zeichen 0ģ127 in einem Byte kodiert, andere Zeichen werden durch mehrere Bytes mit Werten von ³ber 127 kodiert. |
| 5. Links & verwandte Themen |
|
|
|
|
|
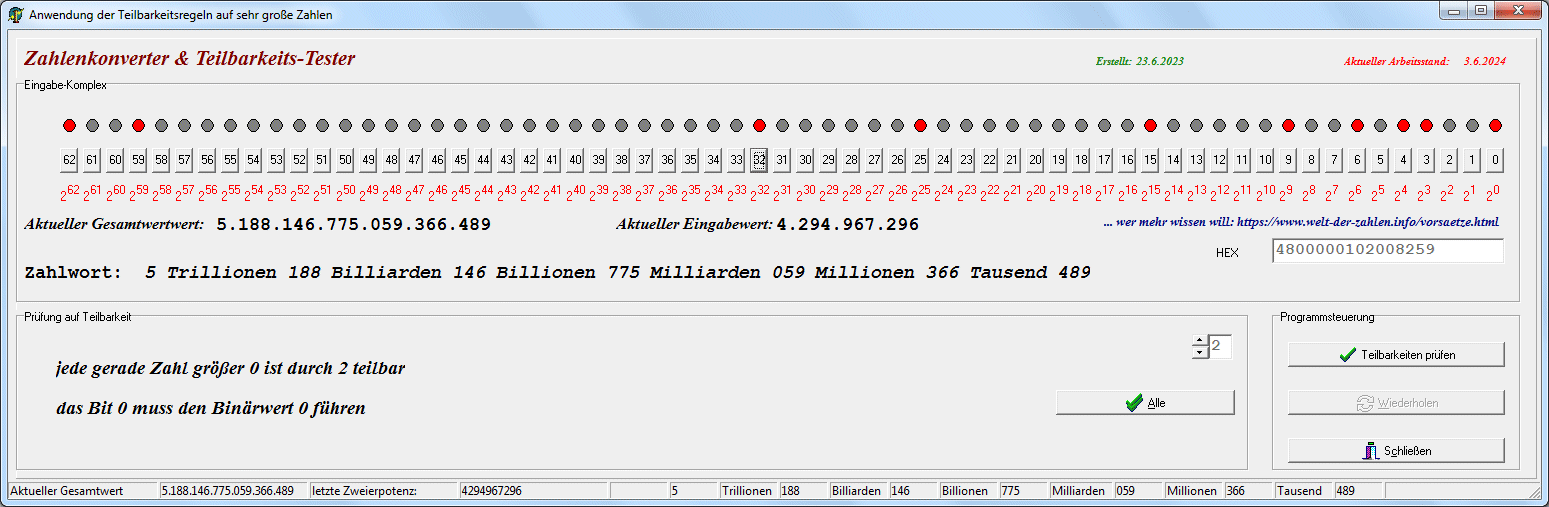
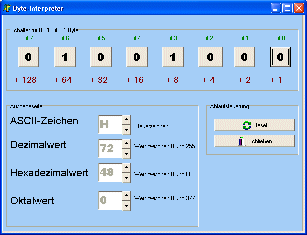
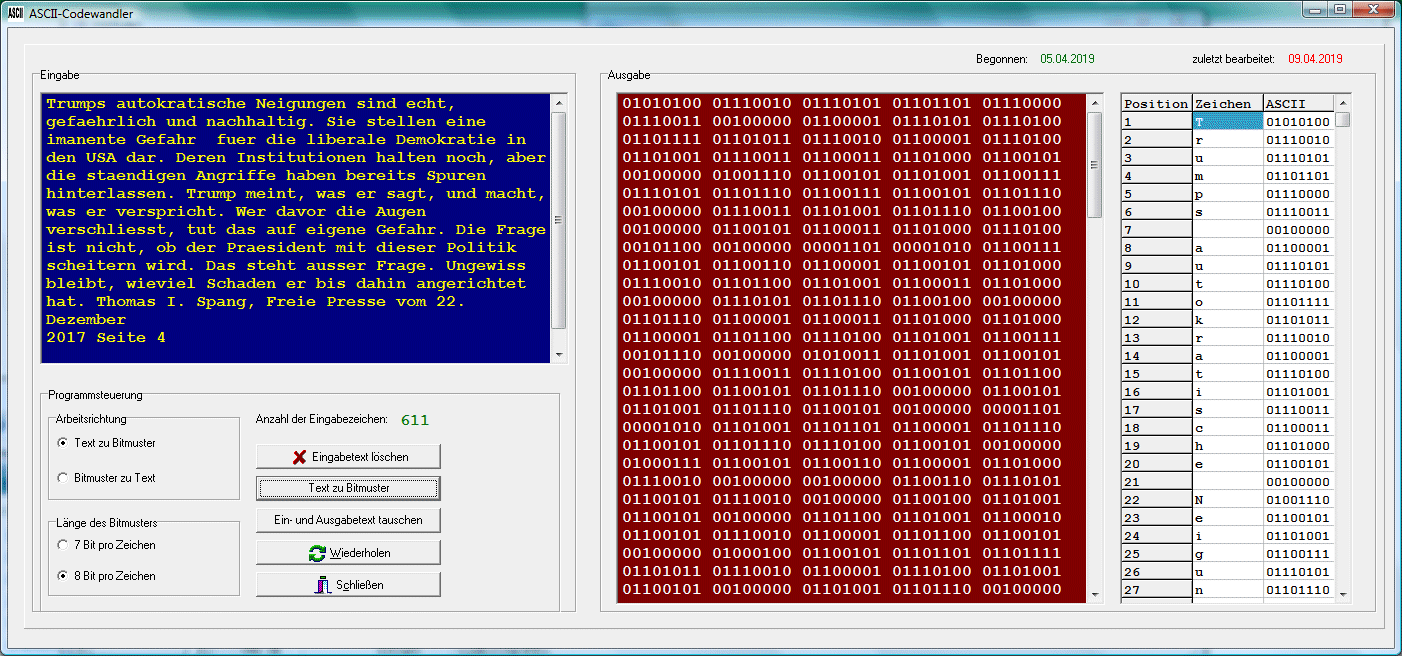
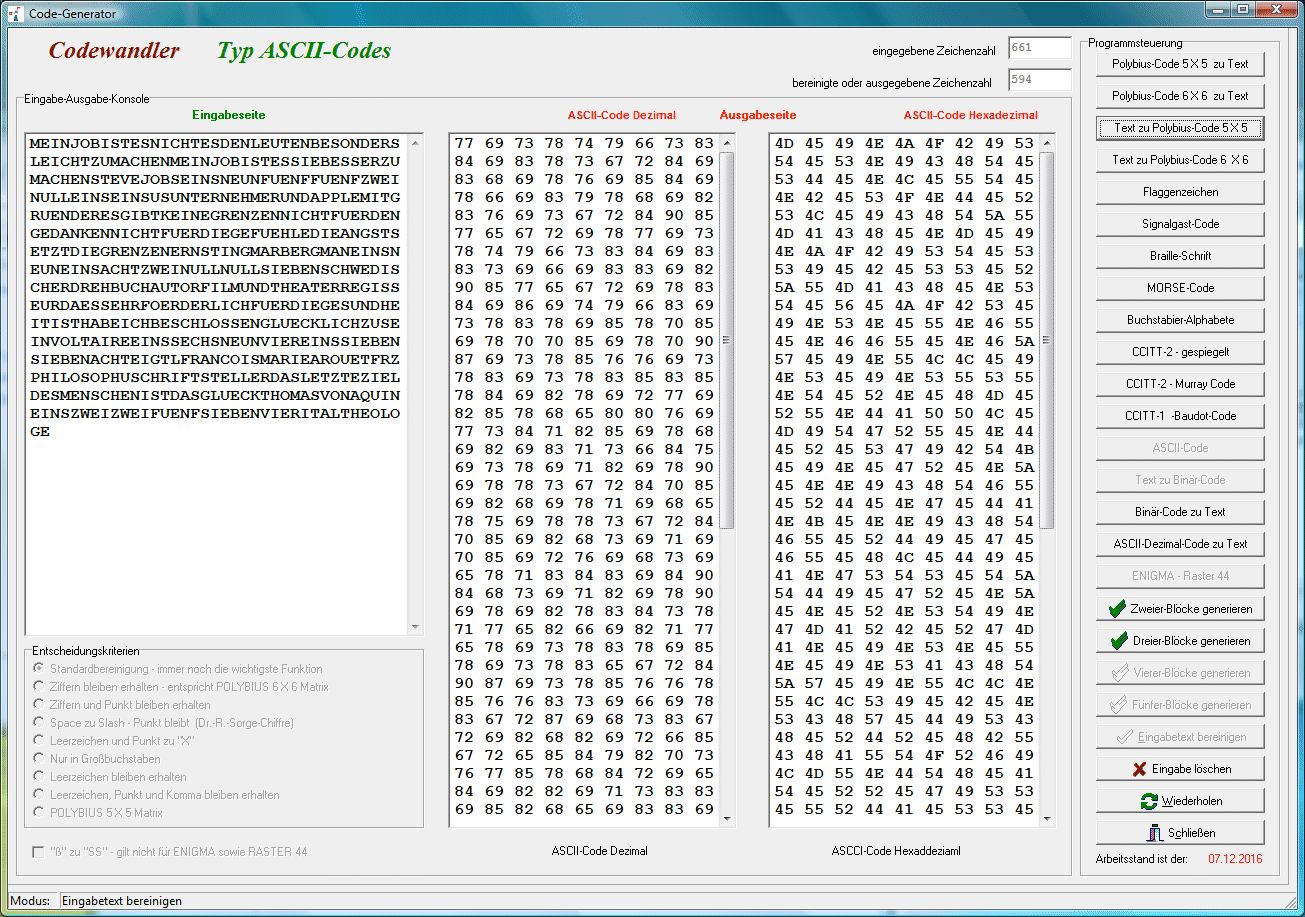
Nun ist der ASCII-Code wie kaum ein anderer Code prõtestiniert, zu eigentlich allem, was mit Computern zu tun hat (und das zieht sich bis auf die Ebene der Mikrocontroller herunter) ein verwandtschaftliches Verhõltnis zu besitzen. | ||||||||||||
|
|
zur Hauptseite |
® Samuel-von-Pufendorf-Gymnasium Fl÷ha | ® Frank Rost am 18. November 2009 |
|
... dieser Text wurde nach den Regeln irgendeiner Rechtschreibreform verfasst - ich hab' irgendwann einmal beschlossen, an diesem Zirkus nicht mehr teilzunehemn ;-) äDieses Land braucht eine Steuerreform, dieses Land braucht eine Rentenreform - wir schreiben Schiffahrt mit drei äfō!ō Diddi Hallervorden, dt. Komiker und Kabarettist |
|
Diese Seite wurde ohne Zusatz irgendwelcher Konversationsstoffe erstellt ;-) |
![]()




{kind=link}
{kind=link}
{kind=link}
{kind=link}